Boosting Performance: The Power of Read Replicas in Database Management.
Introduction
In the ever-evolving landscape of data-driven applications, performance is a critical factor that can make or break user experiences. Database management plays a pivotal role in this scenario, and one effective strategy for enhancing performance is the use of read replicas. If your database server goes down or is incredibly choked due to high volume and starts grinding to a halt, it doesn’t really matter if your application servers are still up — they wouldn’t be able to do useful things for your user without talking to the database server.
The Cloud gives us a really easy way to scale database compute capacity and resilience: the Read Replica!
What’s a Read Replica?
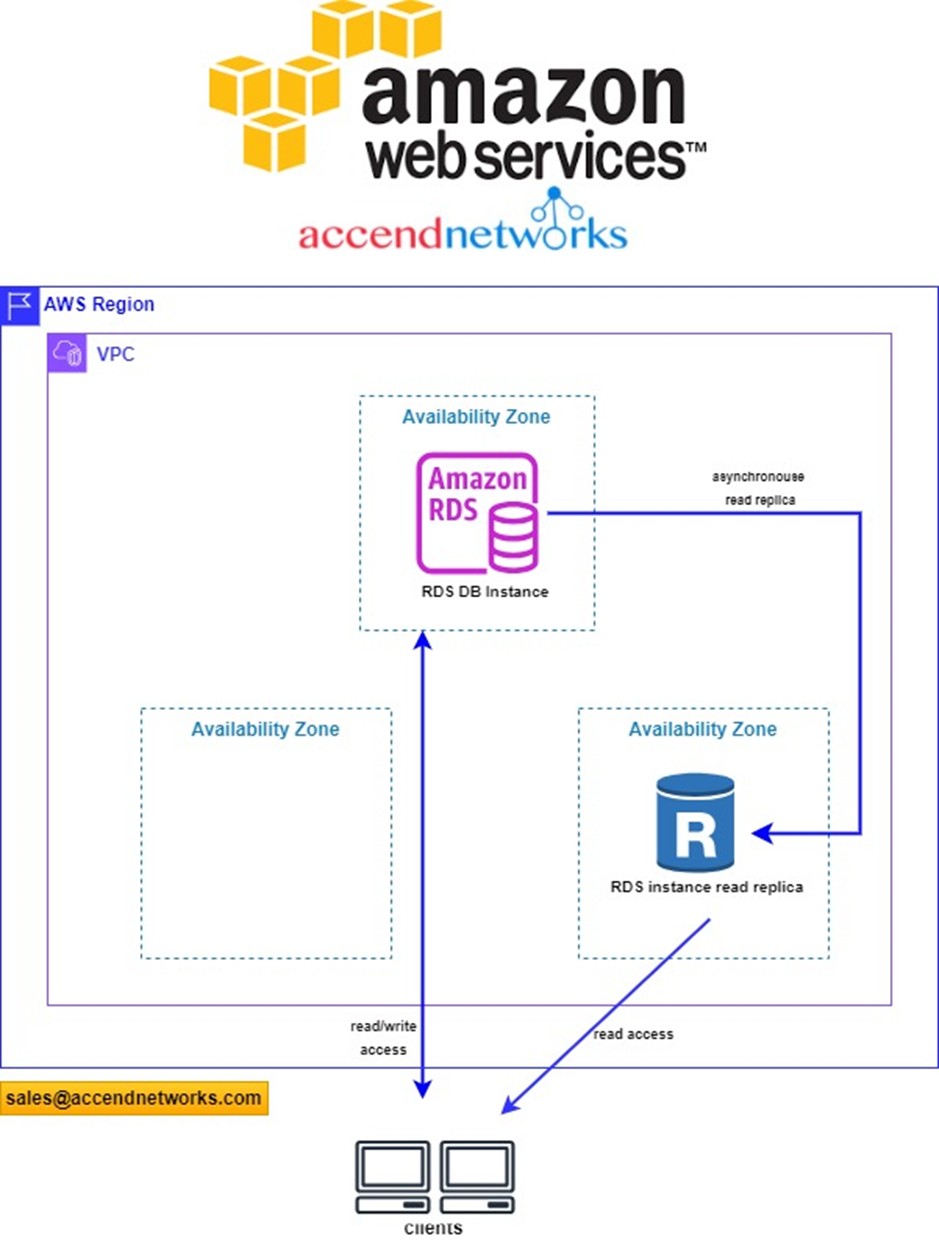
A read replica is a read-only copy of a DB instance. You can reduce the load on your primary DB instance by routing queries from your applications to the read replica. In this way, you can elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads.
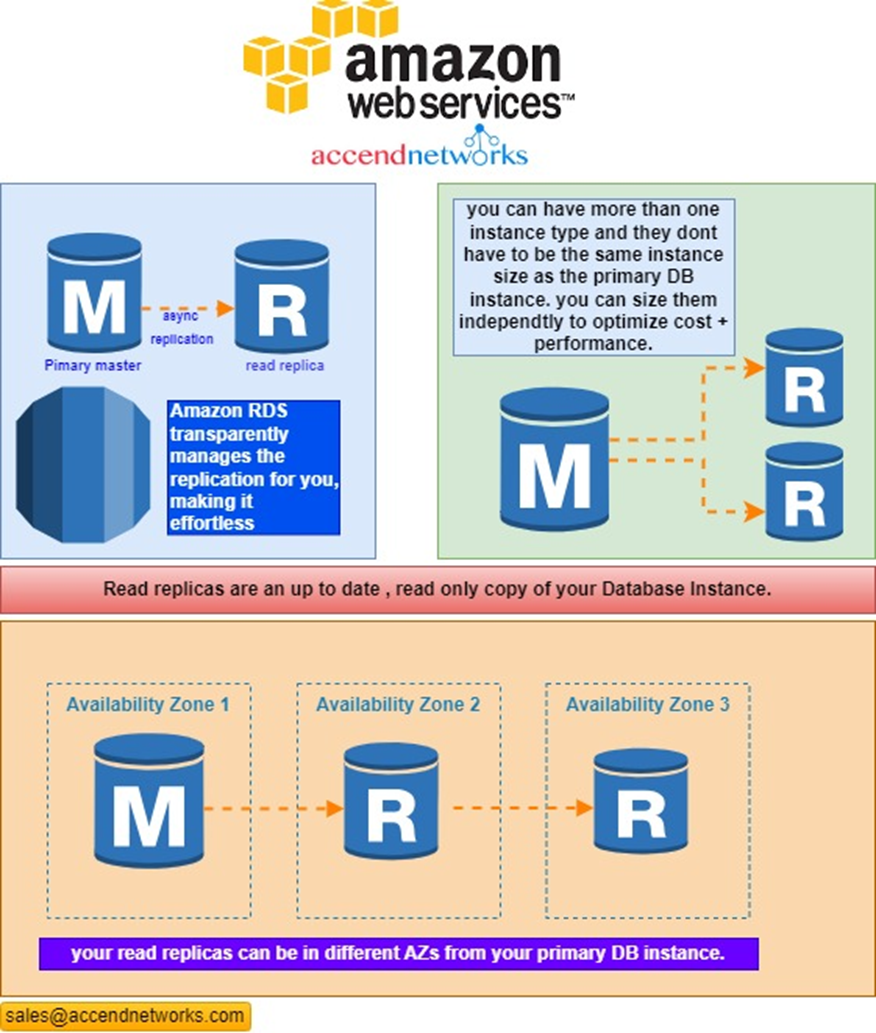
In AWS, Amazon Relational Database Service (RDS) allows you to create read replicas of your primary DB instance with basically zero effort. RDS uses asynchronous replication to keep the read replicas up-to-date with the master. The specific replication technology used varies, depending on what database engine your primary DB uses (e.g., MySQL, Oracle, PostgreSQL, etc)
Read replicas have distinct endpoints, different from the primary DB instance. Your application will have to be configured to connect to the correct endpoint (primary vs read replica), depending on what it needs to do. That means read-write workloads are directed to the primary DB endpoint, while your read-only workloads (e.g., dashboards and report generation) are directed to the read replica.
Read replicas are not free — they are priced just like a primary instance. If your read replica is the same size as your primary instance, then it would cost the same. If it is larger or smaller (read replicas don’t need to be exactly the same size as the primary DB instance), then the pricing adjusts as you would expect.
OK, So What’s a Read Replica Good For?
The primary benefit of a read replica is making your database more performant. Since a read replica is effectively a duplicate server, you get that extra compute capacity for your database needs.
And it’s not just that you get twice the computing power — it’s how you get it.
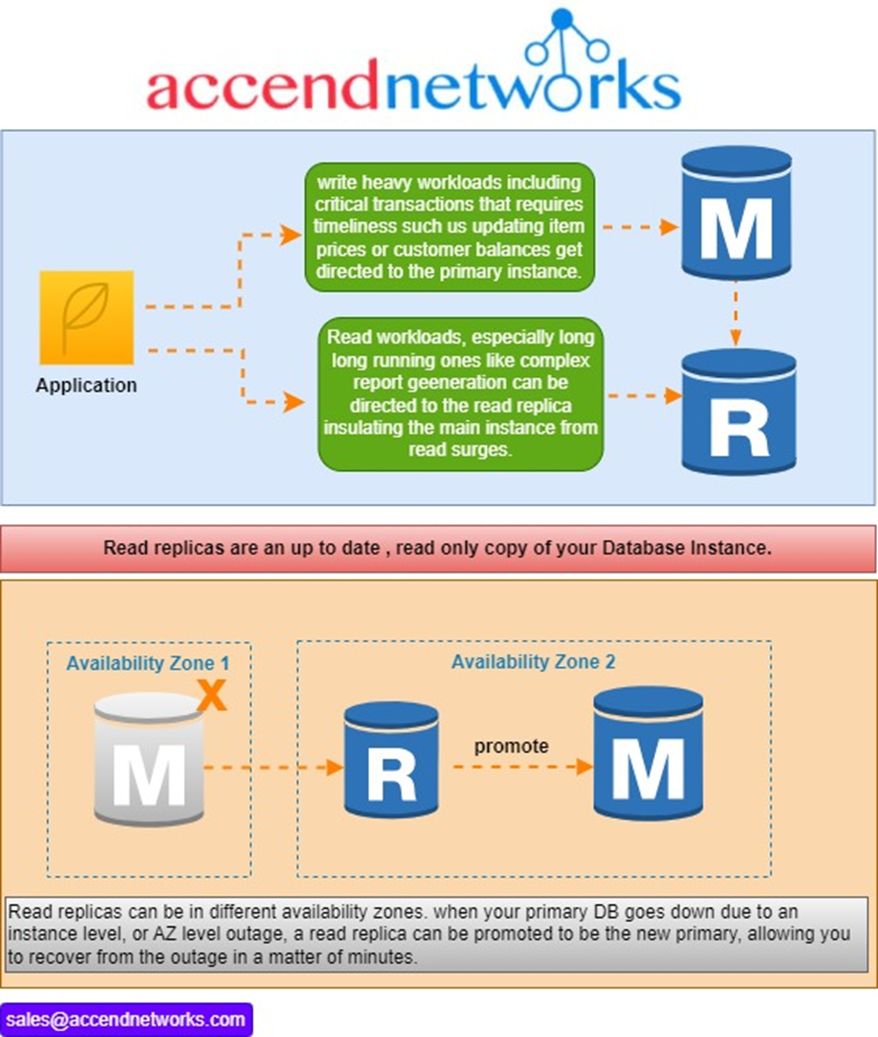
If you doubled the size of your primary DB instance, instead of adding a read replica to it, sure, you’d get equivalent total specs. But with the read replica setup, you can effectively partition your workloads so that heavy read processing can’t bog down your critical transaction processing. If you merely doubled the size of the primary DB instance, a surge of heavy report generation and dashboarding could suddenly slow down the entire DB instance and affect other areas of your application.
And that’s not all! Read replicas also give you an availability improvement. If you wanted Availability Zone (AZ)-level high availability, you could place your read replica in a different AZ from your primary DB instance. When your primary DB goes down, whether just an instance problem or a legitimate AZ-level service disruption, your read replica can be promoted to be a standalone DB, becoming the new primary DB instance. This takes only minutes — a lot faster than if you had to manually create a new primary DB instance from scratch using a backup.
How read replicas work
When you create a read replica, you first specify an existing DB instance as the source. Then Amazon RDS takes a snapshot of the source instance and creates a read-only instance from the snapshot. Amazon RDS then uses the asynchronous replication method for the DB engine to update the read replica whenever there is a change to the primary DB instance.
The read replica operates as a DB instance that allows only read-only connections. An exception is the RDS for the Oracle DB engine, which supports replica databases in mounted mode. A mounted replica doesn’t accept user connections and so can’t serve a read-only workload. The primary use for mounted replicas is cross-region disaster recovery. For more information, see Working with Read Replicas for Amazon RDS for Oracle.
Applications connect to a read replica just as they do to any DB instance. Amazon RDS replicates all databases from the source DB instance
Read replicas in a multi-AZ deployment
You can configure a read replica for a DB instance that also has a standby replica configured for high availability in a multi-AZ deployment. Replication with the standby replica is synchronous. Unlike a read replica, a standby replica can’t serve read traffic.
In the following scenario, clients have read/write access to a primary DB instance in one AZ. The primary instance copies update asynchronously to a read replica in a second AZ and also copies them synchronously to a standby replica in a third AZ. Clients have read access only to the read replica.
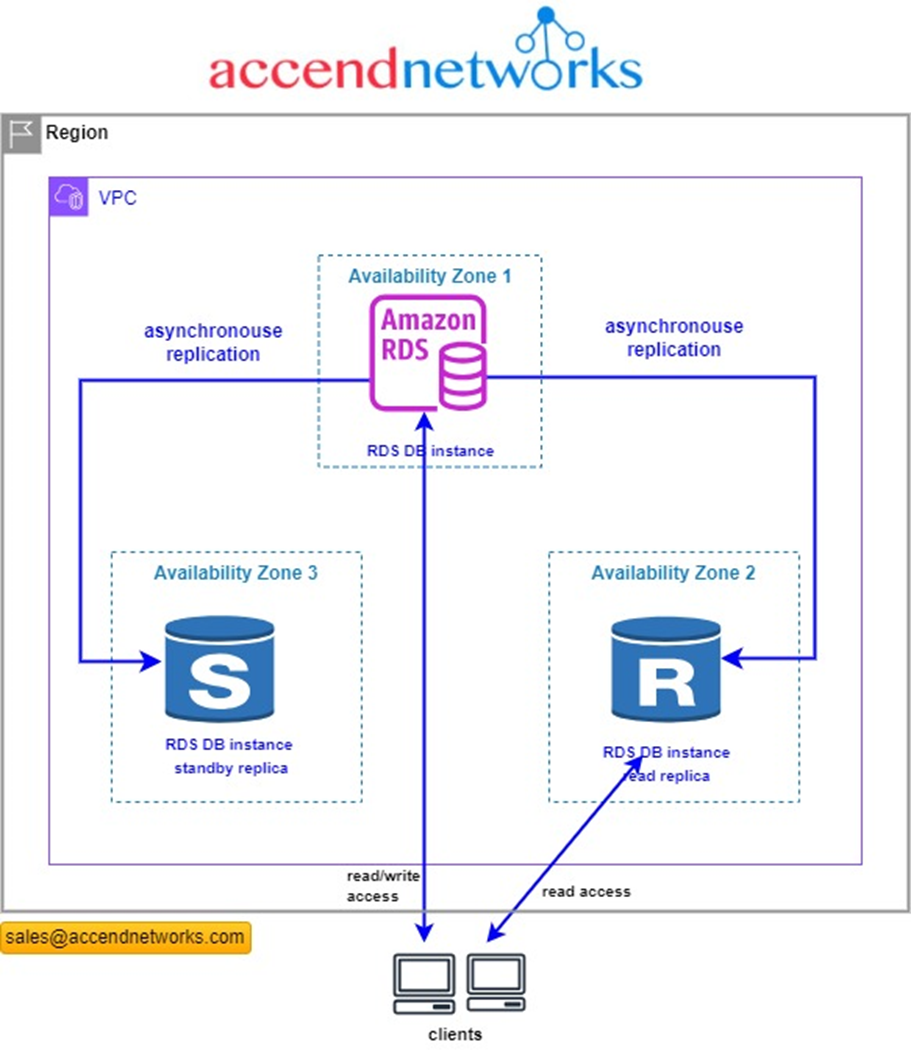
For more information about high availability and standby replicas, see Configuring and managing a Multi-AZ deployment.
Cross-Region read replicas
In some cases, a read replica resides in a different AWS Region from its primary DB instance. In these cases, Amazon RDS sets up a secure communications channel between the primary DB instance and the read replica. Amazon RDS establishes any AWS security configurations needed to enable the secure channel, such as adding security group entries.
Some commendable features of the Read Replicas:
- At most, we can have up to 5 read replicas of any particular database.
- In a bigger organization, where the data is humongous in amount, we can also create read replicas of the Read replicas but this feature comes along with a latency constraint.
- For making, it more scalable at times of heavy workloads, these replicas can also be transformed into independent databases.
- Whenever some hardware failure occurs on the primary database, at that time one of the replicas is promoted as primary in order to reduce the amount of loss that occurred by the failure.
Let us go through the steps involved in creating a read replica.
Note: As we all know, the concept of replicas is useful for huge organizations as they have a large database to work with. Thus, AWS has not allotted this facility for free tier accounts as we individuals do not need this service.
Login into your AWS account, in the search box type RDS then select RDS under service.
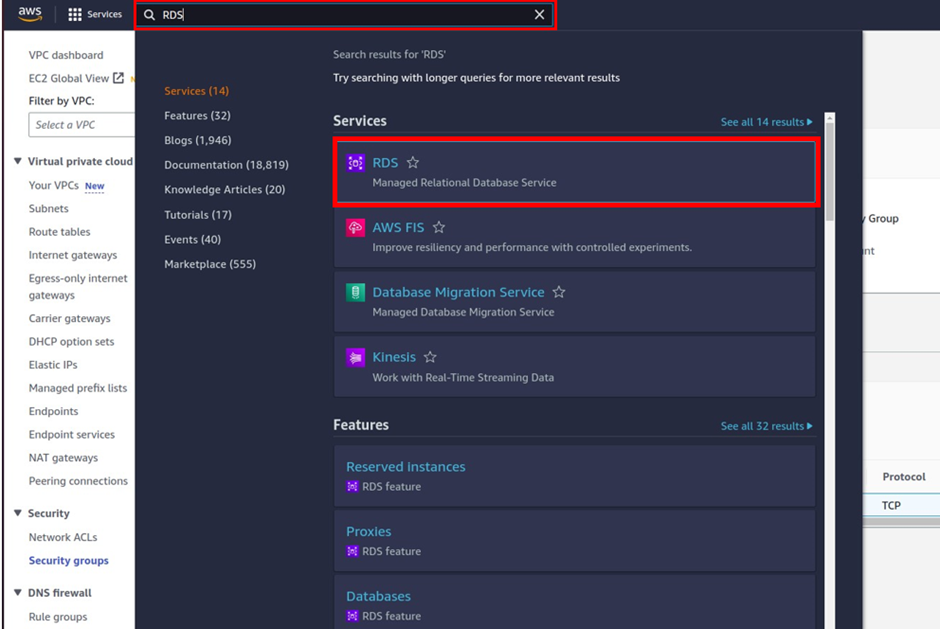
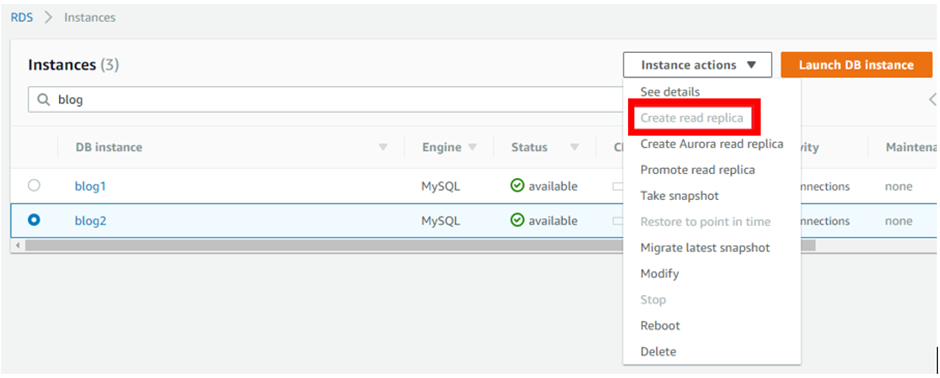
Select the database you want to make read replicas of. From “Actions” choose “Read Replicas”.
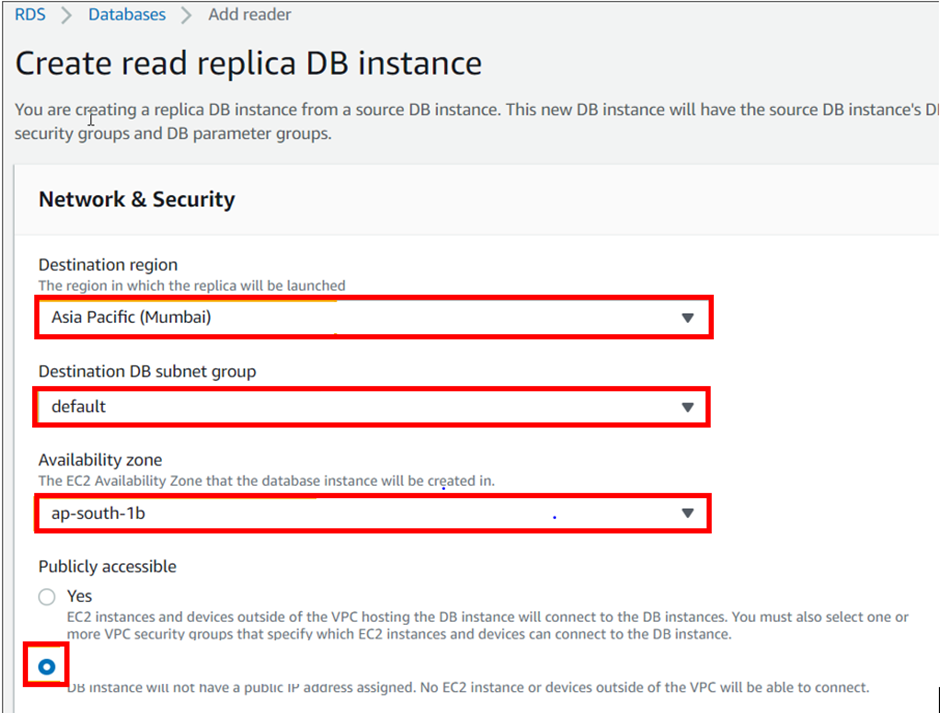
In the create-read replica DB instance dashboard, align all the configurations as per your requirements.
When you find everything appropriately configured as per the needs. Click on “Create Read Replica”.
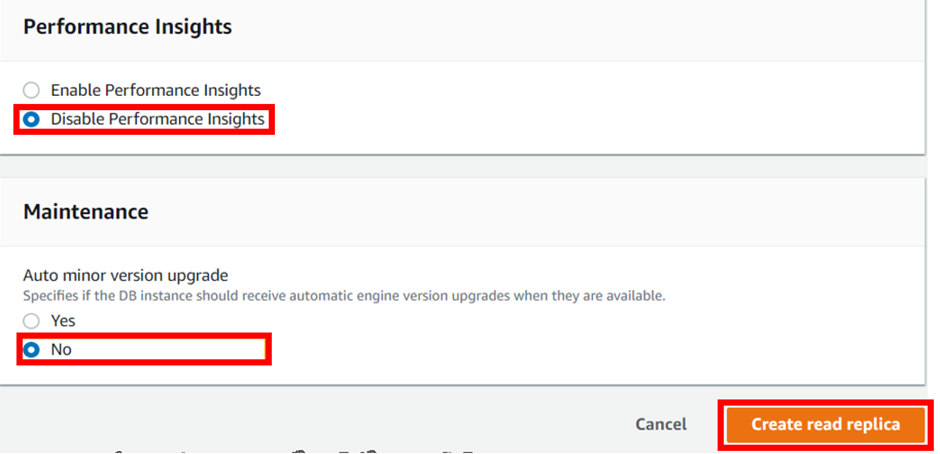
Make sure to pull everything down, to avoid surprise bills.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at. sales@accendnetworks.com
Thank you!
Your article helped me a lot, is there any more related content? Thanks! gate io推荐代码
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.info/register?ref=QCGZMHR6
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
[…] Web Services (AWS) offers a powerful database service known as Amazon Relational Database Service (RDS). It simplifies the process of setting up, operating, and scaling relational databases […]