Turbocharge Your Amazon S3: Performance Enhancement Guidelines.

INTRODUCTION
Amazon S3, Amazon Web Services’ versatile storage service, is the backbone of modern data management. In this blog, we present a concise set of guidelines and strategies to boost your Amazon S3 storage performance.
AWS recommended best practices to optimize performance.
Using prefixes
A prefix is nothing but an object path. When we create a new s3 bucket, we define our bucket name, and later regarding the path or URL, we have directories so that we can have dirA, and a directory subB and then last, we have our object name so that it could be documentA.pdf
bucketName/dirA/subB/documentA.pdf
the s3 prefix is just folders inside our buckets. So, in the example above, the s3 prefix will be /dirA/subB.
How can the S3 prefix give us a better performance?
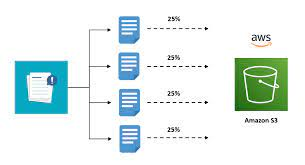
The AWS S3 has a remarkably low latency, and you can reach the first bite out of s3 within approximately 200ms and even achieve an increased number of requests. For example, your application can achieve at least 3,500 PUT/COPY/POST/DELETE and 5,500 GET/HEAD requests per second per prefix in a bucket. And there is no limit on prefix numbers. So, the more prefix you have inside your buckets, the more increased performance you’ll be capable of getting.
The essential number is to look at, 5500 GET requests. For example, if we try to access an object in one of the specific s3 buckets, performing a GET request, gets 5500 requests per second per prefix. So, it means that if we wanted to get more satisfactory performance out of s3 in terms of GET, what we would do is spread our reads across various folders.
If we were to use four different types of prefixes, we would get 5500 requests times 4, which would provide us 22000 requests per second which is a more satisfactory performance.
Optimize s3 performance on uploads, use multipart Upload:
For files, more significant in size than 5GB, it is mandatory to use multi-part upload. But for files more significant than 100MB, it has been recommended to use it as well. What does a multi-part upload do? For example, for a big file, you are cutting it into pieces, then you’re uploading those pieces simultaneously, and this is parallel upload which improves your efficiency. hence, speeding up transfers.
Implement Retries for Latency-Critical Applications:
Utilize Both Amazon S3 and Amazon EC2 within the Same Region:
S3 Transfer Acceleration:
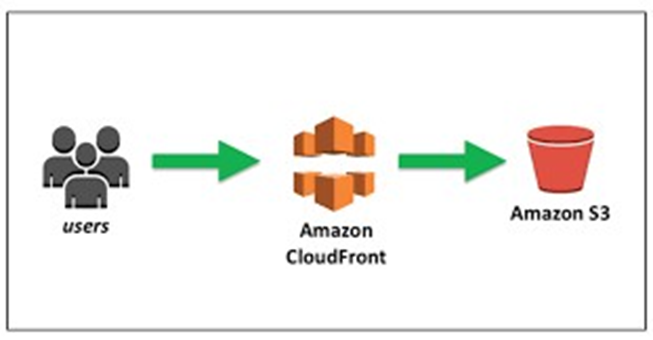
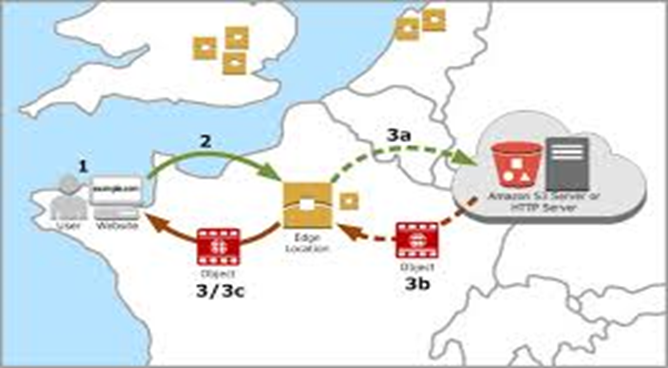
Transfer Acceleration uses the globally distributed edge locations in CloudFront to accelerate data transport over geographical distances.
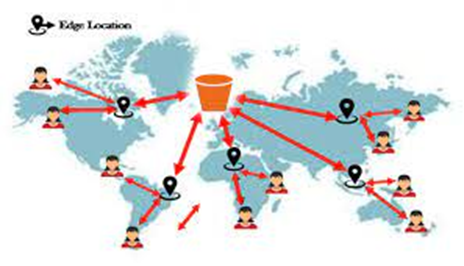
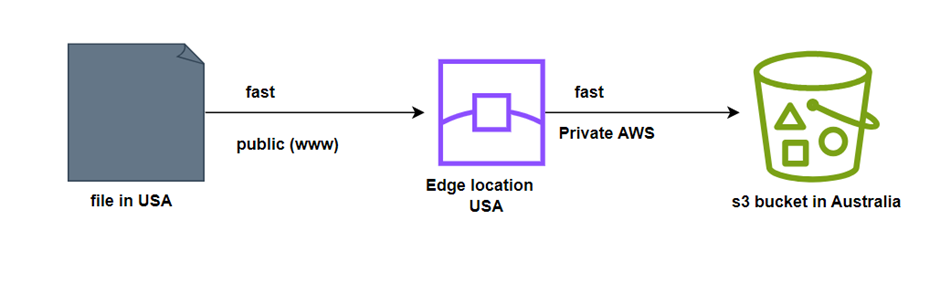
For transferring to the Edge location, it uses a public network and then from the Edge Location to the S3 bucket, it uses the AWS private network which is very fast. Hence, it reduces the use of public networks and maximizes the use of AWS private networks to improve S3 performance.
To implement this, open up the s3 console, and select your bucket. Click on the Properties Tab. Then find the transfer acceleration tab from there. All you have to do is hit enabled and save.
Amazon CloudFront
Is a fast content delivery network (CDN) that transparently caches data from Amazon S3 in a large set of geographically distributed points of presence (Pops).
Evaluate Performance Metrics:
Employ Amazon CloudWatch request metrics specific to Amazon S3, as they include a metric designed to capture 5xx status responses.
Leverage the advanced metrics section within Amazon S3 Storage Lens to access the count of 503 (Service Unavailable) errors.
By enabling server access logging for Amazon S3, you can filter and assess all incoming requests that trigger 503 (Internal Error) responses.
Keep AWS SDKs Up to Date: The AWS SDKs embody recommended performance practices. They offer a simplified API for Amazon S3 interaction, are regularly updated to adhere to the latest best practices, and incorporate features like automatic retries for HTTP 503 errors.
Limitations with s3,
Suppose we use the Key Management Service (KMS), Amazon’s encryption service. In that case, if you enabled the SSE-KMS to encrypt and decrypt your objects on s3, you must remember that there are built-in limitations, within the KMS function ‘generate data key’ in the KMS API. Also, the same situation happens when we download a file. We call the decrypt function from the KMS API. The essential information and the built-in limits are region-specific; however, it will be around 5500, 10000, or 30000 requests per second, and uploading and downloading will depend on the KMS quota. And nowadays we can’t ask for a quota expansion of KMS.
If you need performance and encryption simultaneously, then you just think of utilizing the native S3 encryption that’s built-in rather than utilizing the KMS.
If you are looking at a KMS issue, it could be that you’re reaching the KMS limit, which could be what’s pushing your downloads or requests to be slower.
Stay tuned for more.
If you have any questions concerning this article, or have an AWS project that require our assistance, please reach out to us by leaving a comment below or email us at. sales@accendnetworks.com
Thank you!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/en-NG/register-person?ref=YY80CKRN
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/it/register-person?ref=P9L9FQKY
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your article helped me a lot, is there any more related content? Thanks!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your article helped me a lot, is there any more related content? Thanks! binance
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thank you, your article surprised me, there is such an excellent point of view. Thank you for sharing, I learned a lot.
Your article helped me a lot, is there any more related content? Thanks!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.