Protecting Sensitive Data in AWS: A Practical Demo with AWS Macie
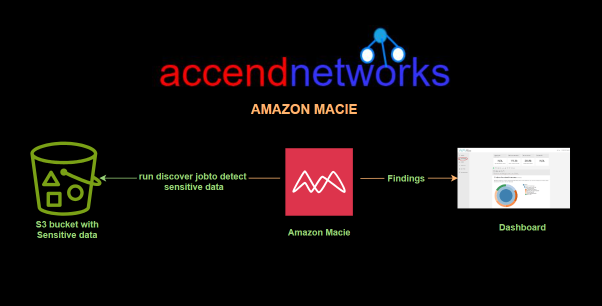
In today’s digital landscape, keeping sensitive data safe has become essential. As cloud environments grow more complex, it’s crucial to protect your sensitive data from unauthorized access and leaks. Amazon Macie is a powerful service designed to automatically discover, classify, and protect sensitive data stored in AWS. In this article, we will provide a hands-on demo to walk you through the process of using AWS Macie to enhance your data security and explore its features.
Challenges Amazon Macie is addressing
With a wide range of data residing across multiple AWS services and regions. Identifying and safeguarding this data manually can be a daunting task. AWS Macie steps in as a guardian, utilizing advanced machine learning algorithms and pattern recognition to automate the process of data discovery and classification.
AWS Macie and It’s Functions
Discover Sensitive Data: AWS Macie thoroughly scans data repositories, such as Amazon S3 buckets to identify a broad spectrum of sensitive information. Doing so assists organizations in gaining full visibility into their data landscape.
Intelligent Threat Detection: Macie not only discovers sensitive data but also acts as an ever-watchful sentry. It proactively alerts organizations to any data access or movement that may pose security risks or violate compliance policies.
Compliance and Reporting: Macie streamlines this process by generating detailed reports on data security and access, helping organizations demonstrate adherence to industry-specific compliance requirements.
Let’s dive into the hand-son
Step 1 creating S3 bucket.
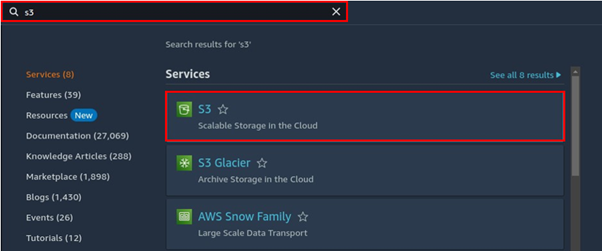
Log in to your AWS management console and in the search bar, type S3 then select S3 under services.
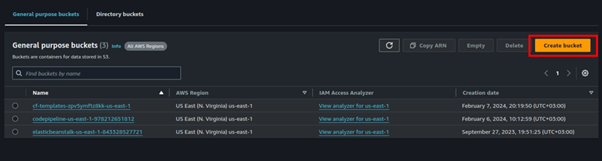
In the S3 console, click Create Bucket.
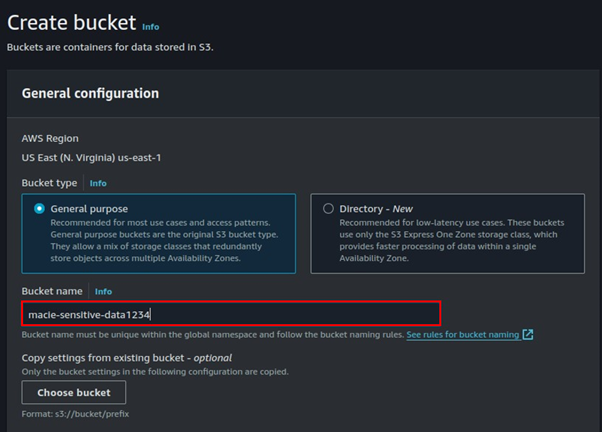
In the create bucket console, fill in your bucket details by entering a unique bucket name.
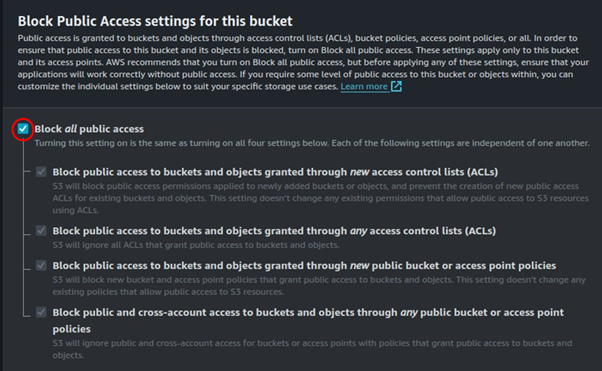
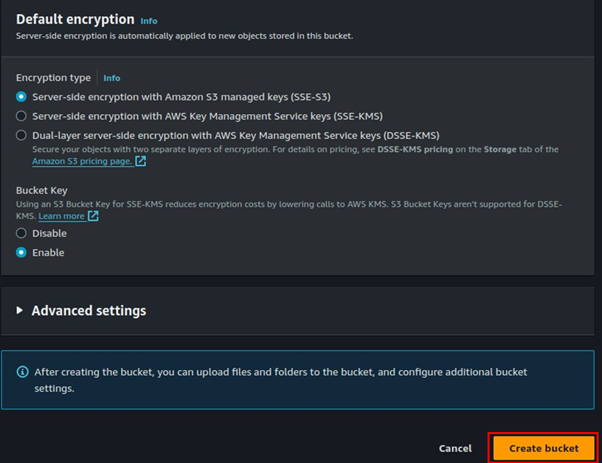
Make sure that all public access check box is ticked. Leave all other settings as default, then scroll down and click Create Bucket.
Step 2 uploading sensitive data into S3 bucket.
Our bucket is successfully created, and we will now upload our sensitive data in our S3 bucket. You can get this sensitive data in this Github link.
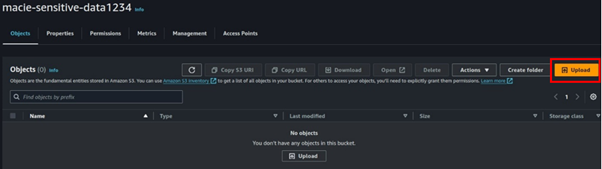
Select your bucket, move to the object tab then click upload.
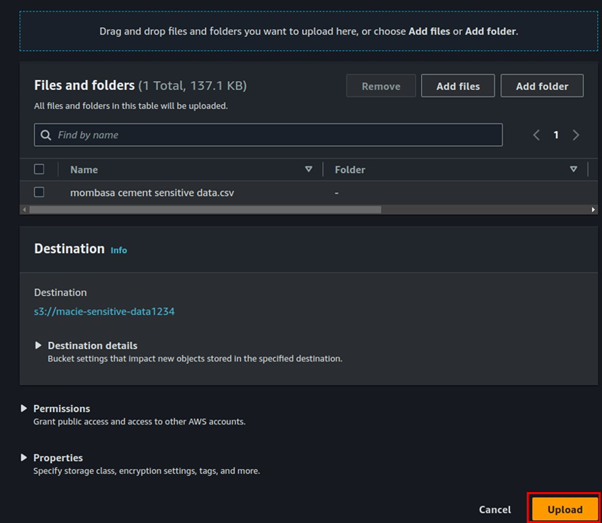
Select the sensitive data you downloaded then click upload.
Step 3 Enabling and configuring Amazon Macie.
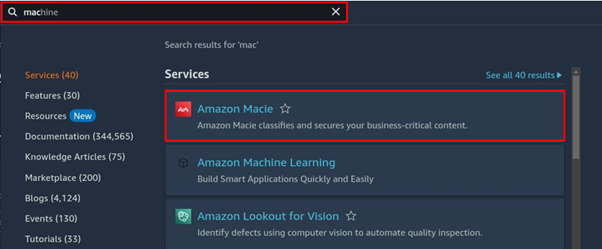
Let’s now head to the Macie console, type Macie in the search bar, and select Mace under services.
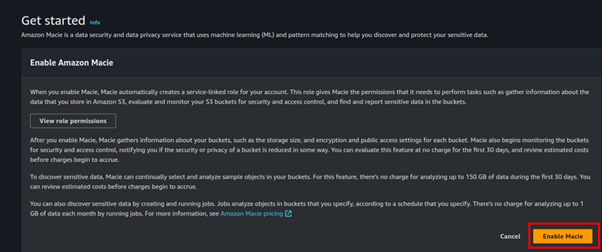
In the Macie console, click Get Started.
In the Get Started dashboard click Enable Macie.
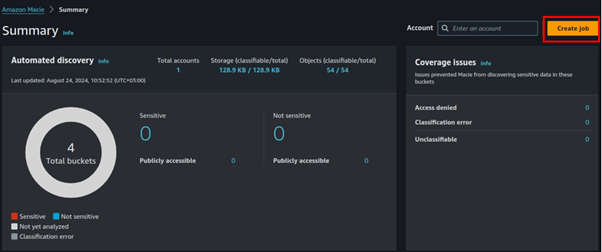
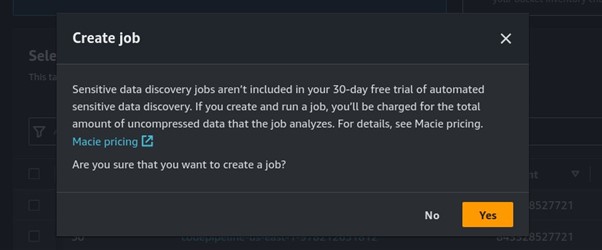
When you click enable Macie, it will start automated discovery. We will create a job for Macie, click Create job.
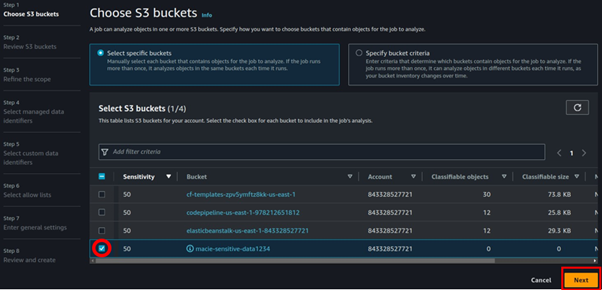
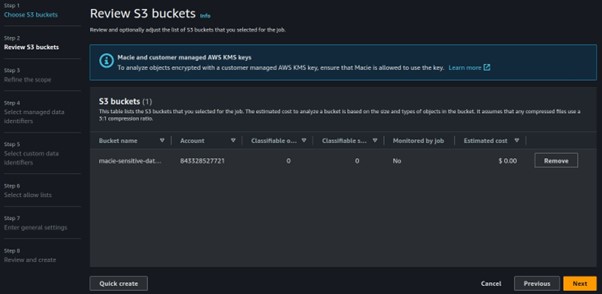
Select the S3 bucket that you intend to run continuous audits on. Then, Click Next again to go to Step Three.
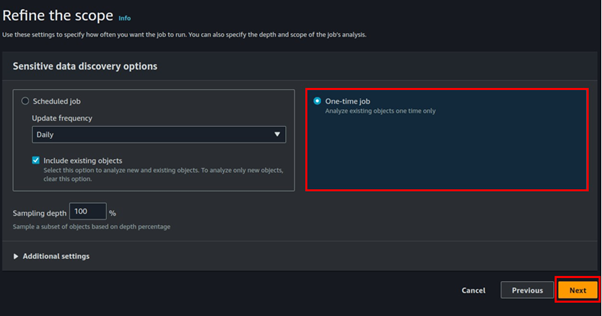
In a real-world environment, we would want to continuously audit for sensitive data on a schedule. However, we only need to scan on-demand. Select a One-time job and click Next.
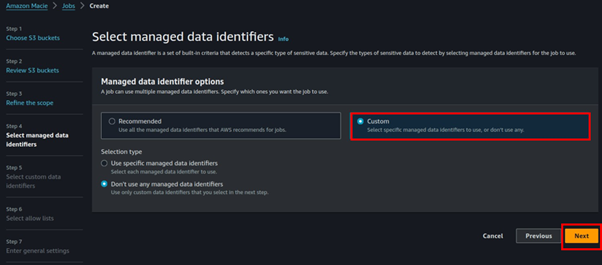
Let us refine the job.
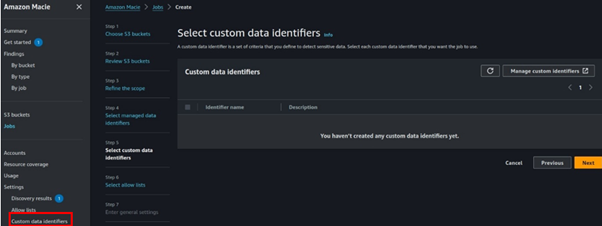
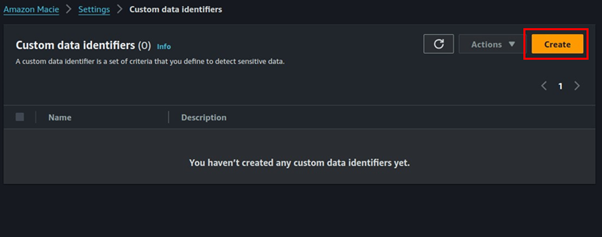
We will create a custom identifier, in the steps of the prompt in creating a job, select manage custom identifiers.
Click Manage Custom Identifiers which takes you to a window where you can define a regex identifier.
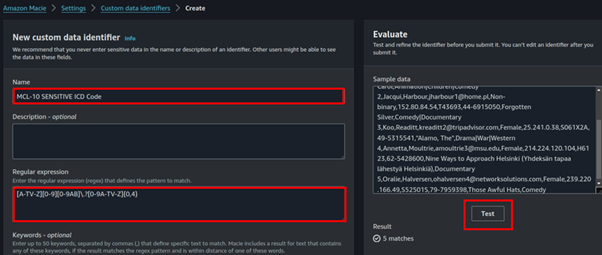
Give the custom data identifier ICD-10 Diagnosis Code and paste the following regular expression field:
[A-TV-Z][0-9][0-9AB]\.?[0-9A-TV-Z]{0,4}
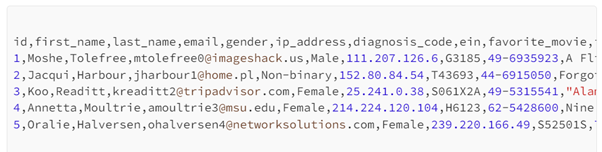
To confirm our Regex works, let’s test some dummy sample data. In the sample data, paste the below data and hit Test
id,first_name,last_name,email,gender,ip_address,diagnosis_code,ein,favorite_movie,favorite_movie_genre
1,Moshe,Tolefree,mtolefree0@imageshack.us,Male,111.207.126.6,G3185,49-6935923,A Flintstones Christmas Carol,Animation|Children|Comedy
2,Jacqui,Harbour,jharbour1@home.pl,Non-binary,152.80.84.54,T43693,44-6915050,Forgotten Silver,Comedy|Documentary
3,Koo,Readitt,kreaditt2@tripadvisor.com,Female,25.241.0.38,S061X2A,49-5315541,”Alamo, The”,Drama|War|Western
4,Annetta,Moultrie,amoultrie3@msu.edu,Female,214.224.120.104,H6123,62-5428600,Nine Ways to Approach Helsinki (Yhdeksän tapaa lähestyä Helsinkiä),Documentary
5,Oralie,Halversen,ohalversen4@networksolutions.com,Female,239.220.166.49,S52501S,79-7959398,Those Awful Hats,Comedy
Once the test is successful, scroll down and click submit.
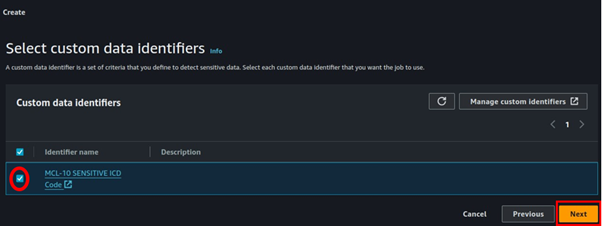
Return to the original window. Hit the refresh button, select the newly created identifier, and click Next.
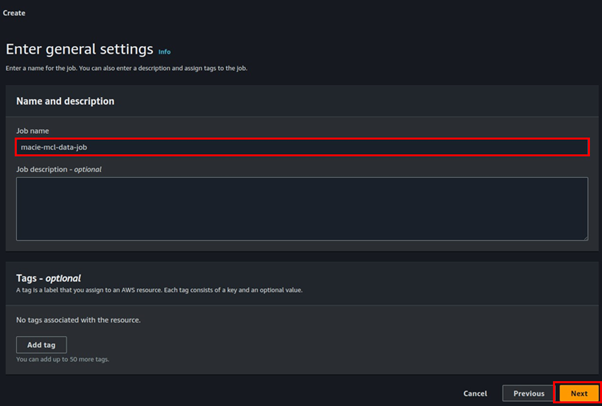
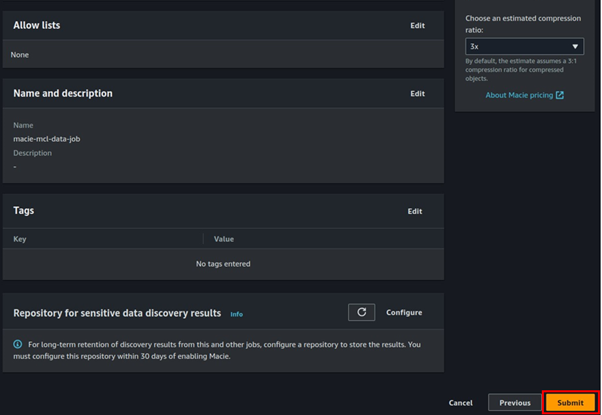
Continue clicking next, under general settings, enter job name.
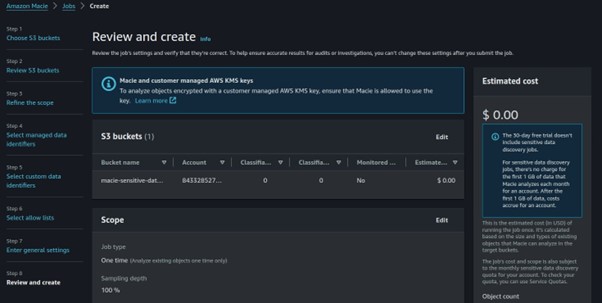
Click next, review then hit the submit button.
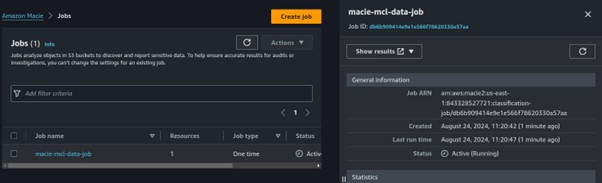
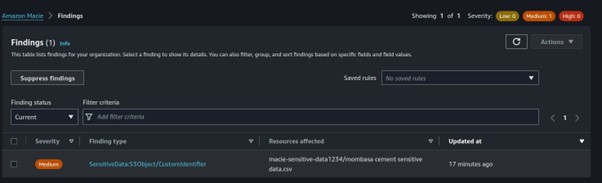
At this point, the job will run for roughly 10–15 minutes. When the status moves from Active (Running) to Complete. Then we will proceed to the findings on the sidebar and you will be able to see Macie’s findings.
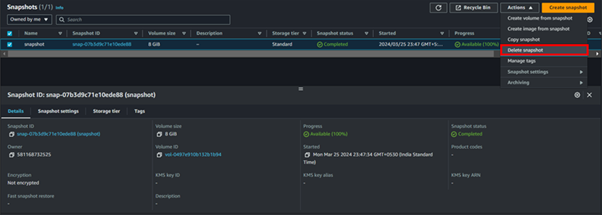
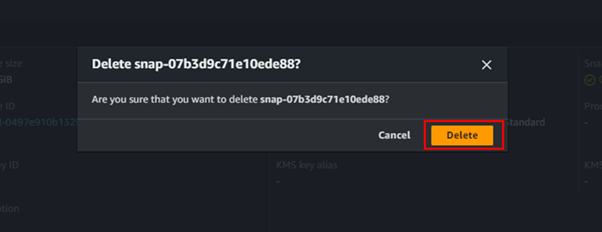
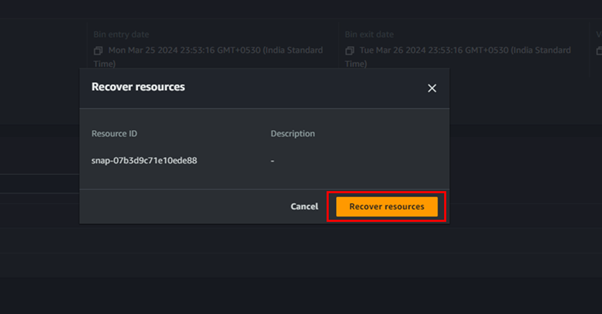
This brings us to the end of this demo, make sure to clean up resources.
Conclusion
Amazon Macie offers a robust solution for securing sensitive data in the cloud by combining advanced machine learning with automated data discovery and classification. By following the above-outlined steps, you’ve learned how to set up and utilize Amazon Macie to protect your sensitive data.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!