Hands-on Demo: Setting Up a VPC Endpoint to Securely Access Amazon S3 bucket
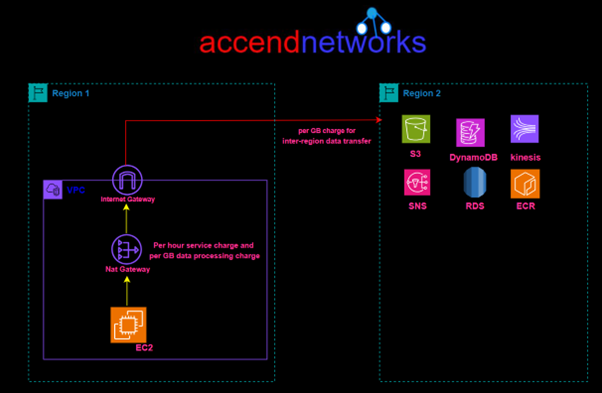
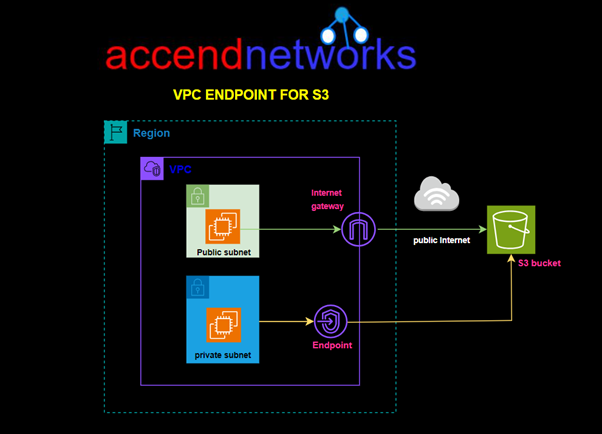
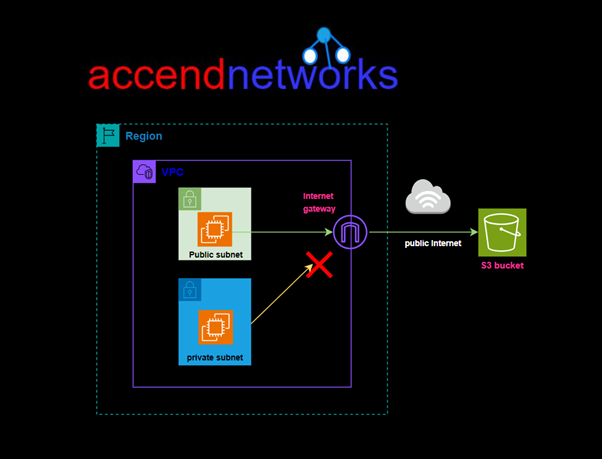
Amazon Virtual Private Cloud (VPC) endpoints let you securely connect your VPC to AWS services, like S3, without using the public internet. This means you don’t need an internet gateway, NAT device, VPN, or Direct Connect to access these services. In this blog, I will walk you through how to set up a VPC endpoint to connect to Amazon S3 securely from within your VPC.
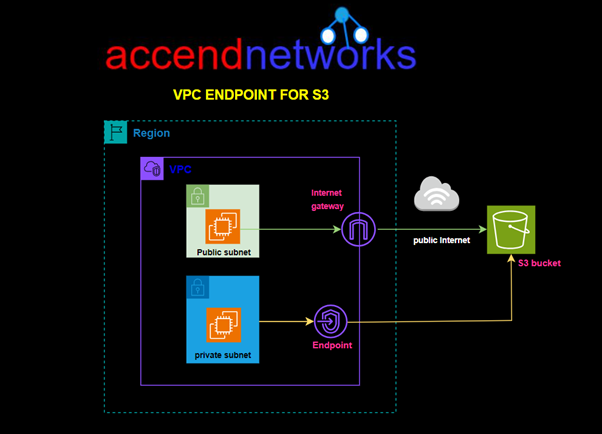
Why VPC Endpoint for S3
VPC Endpoint for S3 provides us a secure link to access resources stored on S3 without routing through the internet. AWS doesn’t charge anything for using this service.
In this hands-on lab, we will create a custom VPC with a public and private subnet, we will then Launch a private EC2 Instance in the private subnet and a public EC2 Instance in the public subnet. We will then create an S3 Gateway endpoint and test connection from the public and private EC2 Instances.
Step 1: Create VPC with public and private subnet
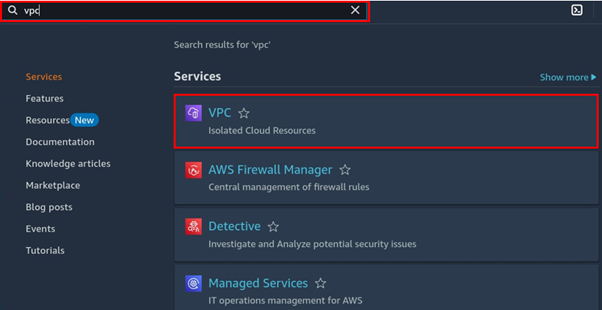
Log into the AWS Console and navigate to the VPC dashboard.
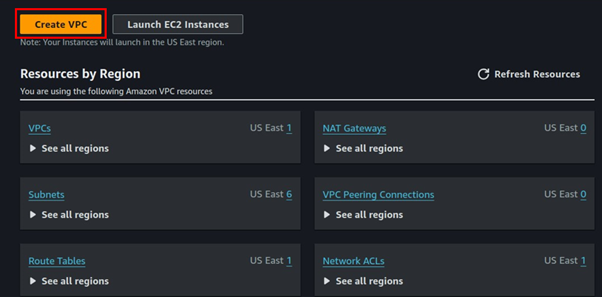
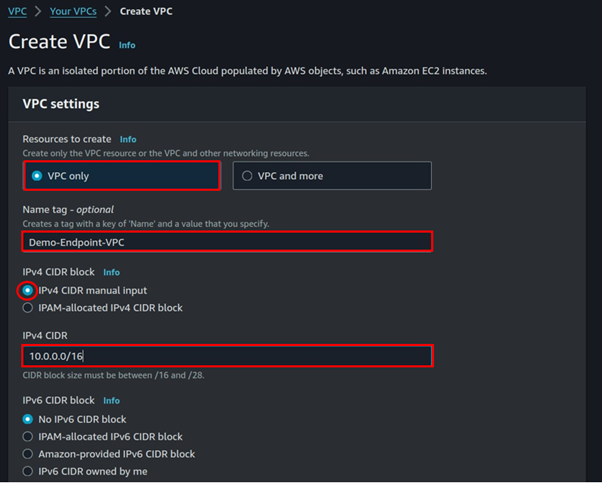
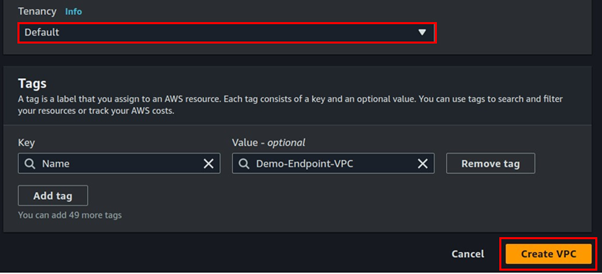
Fill in VPC details, select VPC only, then enter VPC CIDR under IPv4 CIDR, leave it at default tenancy then click Create VPC.
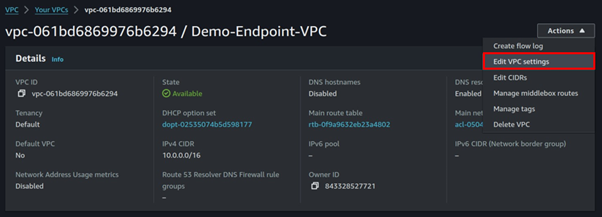
Select the created VPC, and click the actions drop-down button to go to VPC settings.
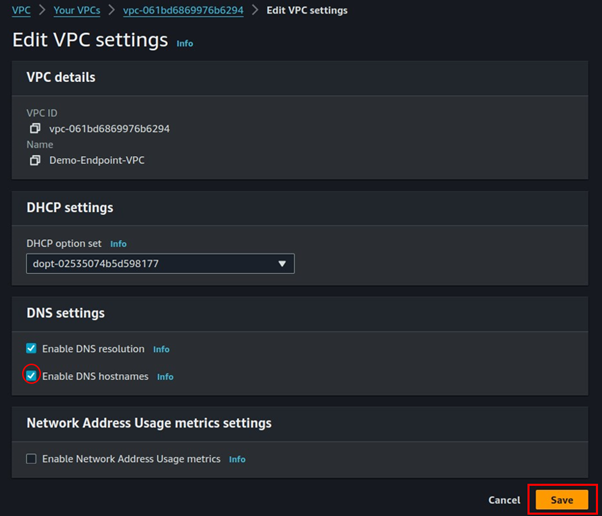
Under DNS settings, check the box on Enable DNS hostnames then click save.
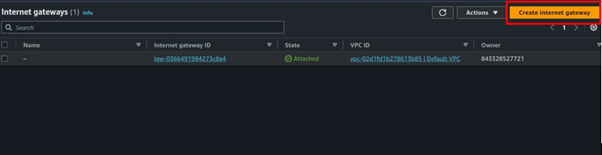
Step 2: Create Internet Gateway and attach it to VPC
Select Internet Gateway on the left side of VPC UI, then click Create Internet Gateway.
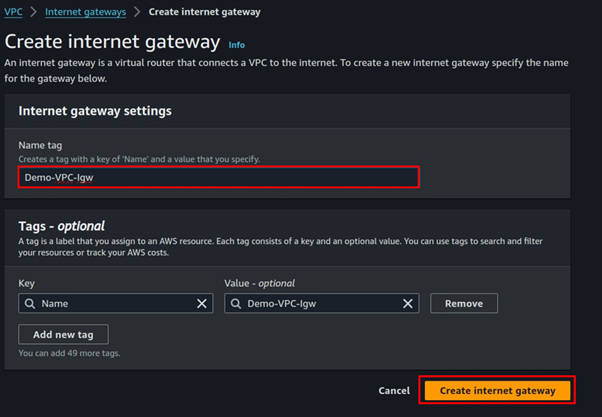
Fill in the details then click Create Internet Gateway.
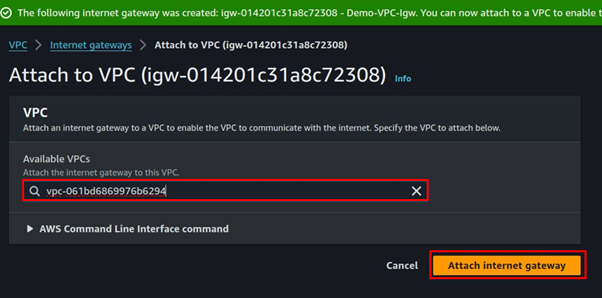
Click the attach button, select the VPC to attach the internet gateway then select attach internet gateway.
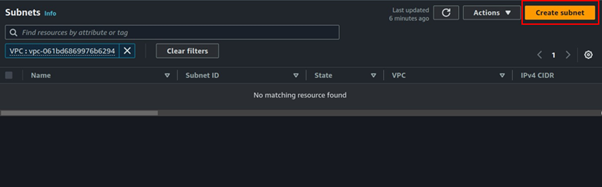
Step 3 create subnets
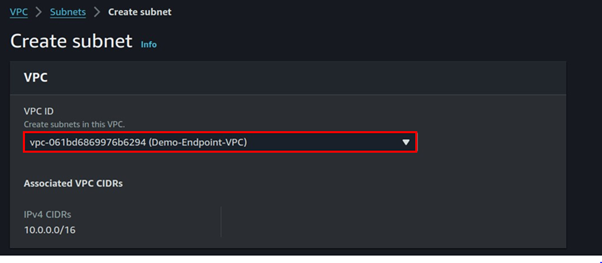
Select subnets in the Left side UI of the VPC dashboard then click Create Subnet.
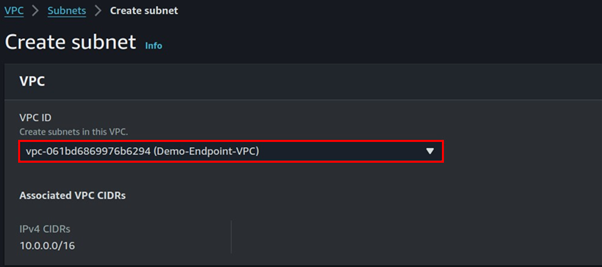
Select the VPC you just created then scroll down.
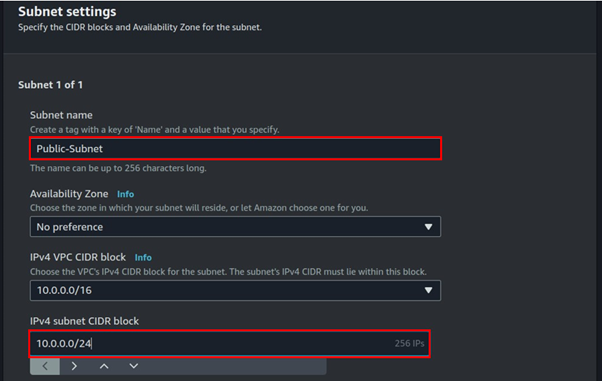
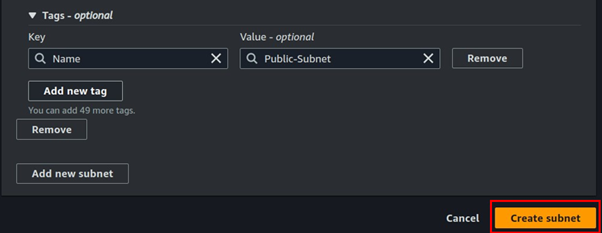
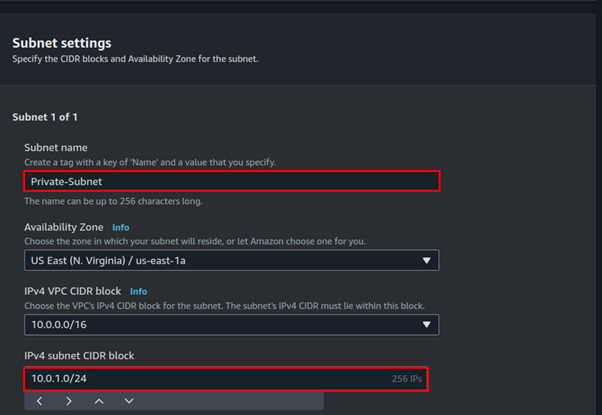
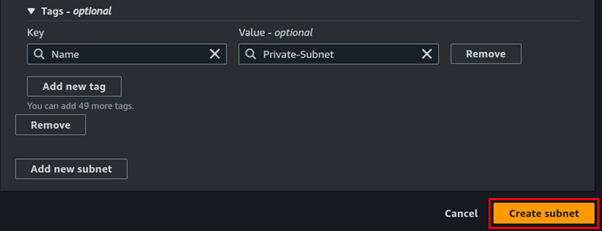
Fill in subnet details, enter your preferred name then for subnet CIDR, enter 10.0.0.0/24, scroll down, and click Create subnet.
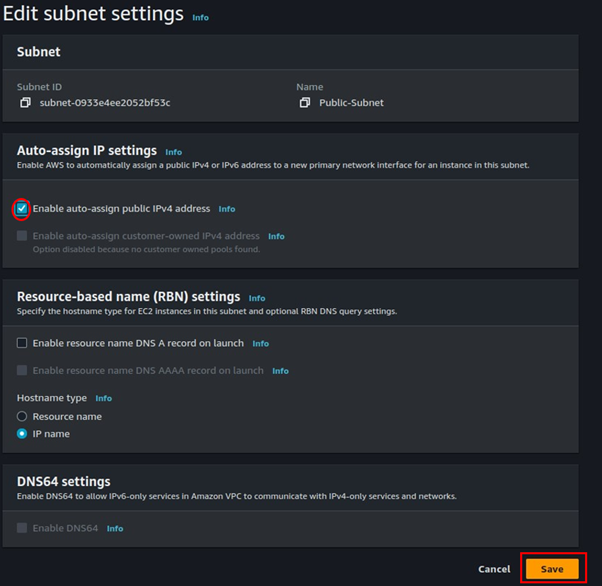
For the public subnet click the Action drop-down button, then navigate to subnet settings then select it. Tick the box enable-auto-assign public IP. Then click save.
Again, click Create subnet, and repeat the above process, but now for IPv4 CIDR enter 10.0.1.0/24, scroll down, and click Create subnet.
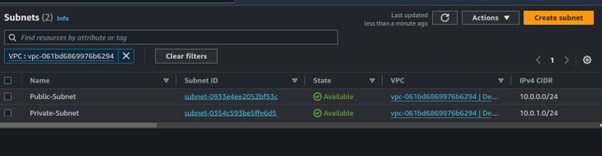
Two subnets were created as you can view them.
Create a Public route table, add a public route to the Internet, and associate the public route with the public subnet.
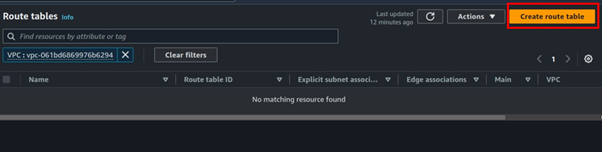
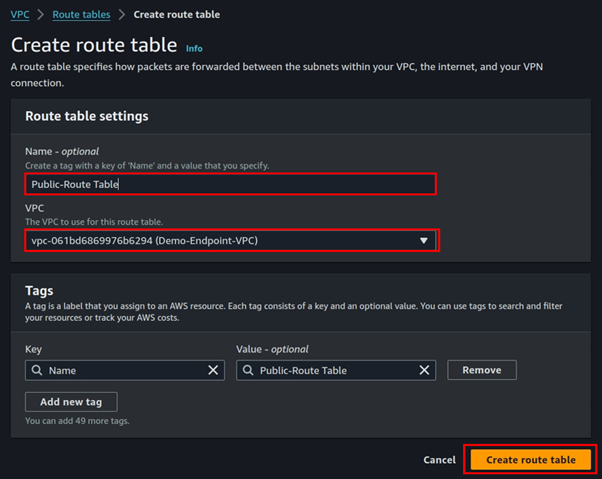
Under route tables, click Create route table.
Call it public Route table, select your VPC, then click Create route table.
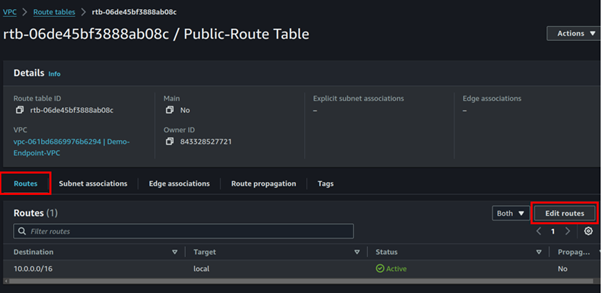
Select the created route table navigate to the routes tab, click edit routes then add route.
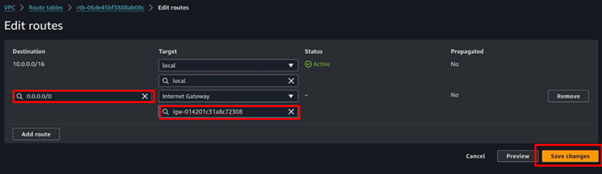
Add the pubic route, 0.0.0.0/24, and destination select the internet gateway of the VPC you created then click save changes.
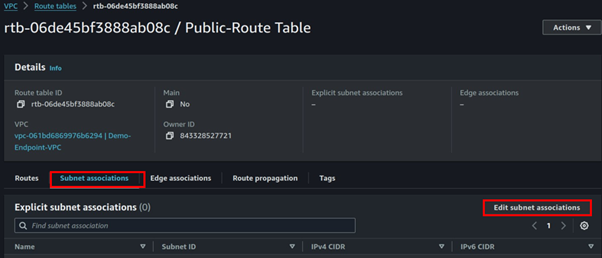
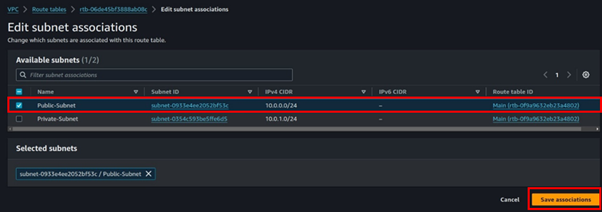
Navigate to the subnet association tab then click Edit associations.
Select the public route table then click Save Associations. The private subnet will be Implicitly associated with the main route table which routes traffic locally within the VPC, hence it’s private by default.
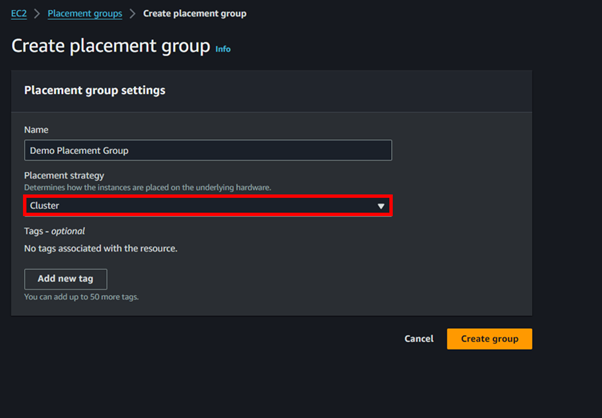
Step 4 create Gateway endpoint
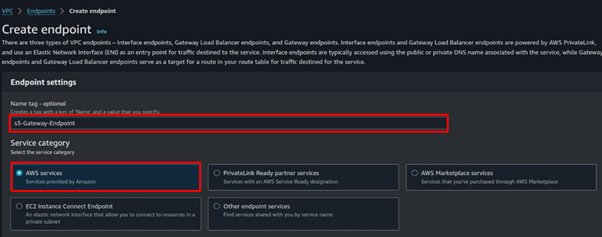
On the left side of VPC UI, select endpoints then click Create Endpoint.
The service category is AWS service.
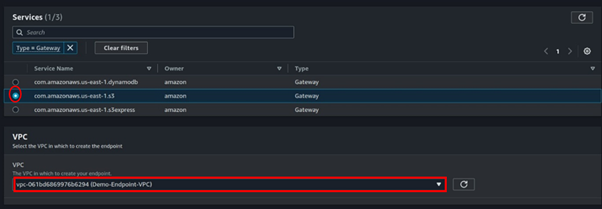
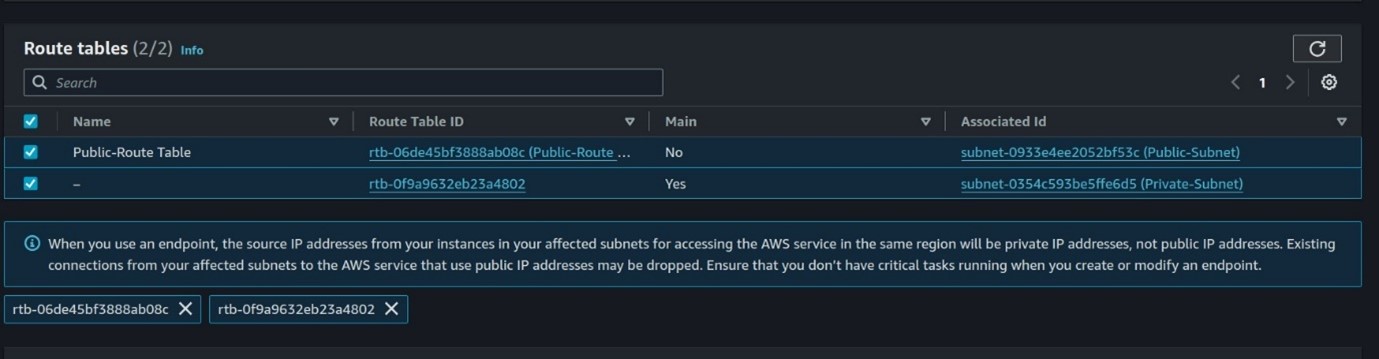
Under services search Gateway then select it. Under the service name select s3 as shown below. For VPC, select your VPC
Select all the route tables.
We will not create a custom policy, move with full access, scroll down, and click create endpoint.
Step 5: Create bucket and upload objects
In the console search bar, look for S3, then select it.
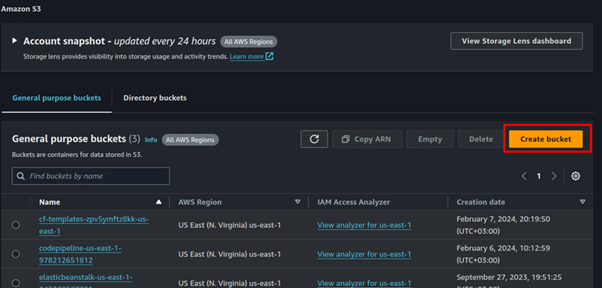
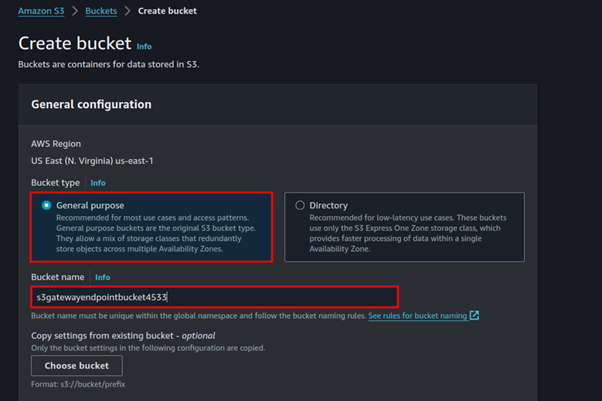
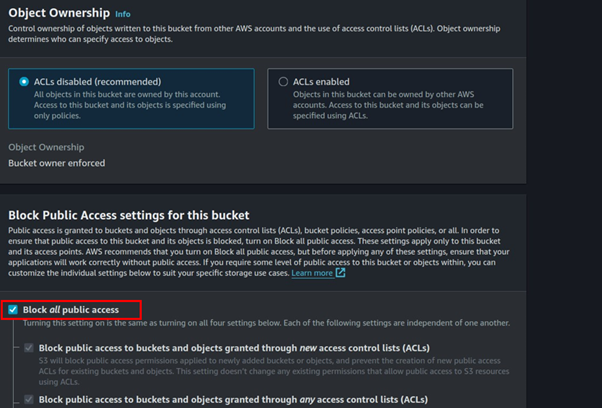
Leave it at general purpose then fill in Bucket name. Block all public access, scroll down, and click Create bucket.
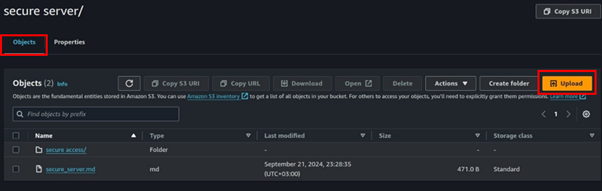
Upload objects to your bucket by Clicking the upload button,
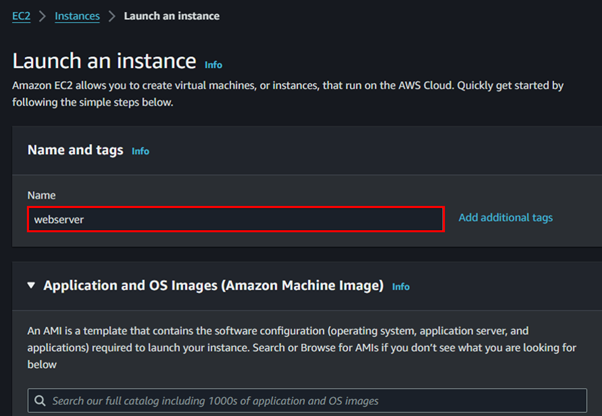
Step 6: Luanch two EC2 Instances, in the private and public subnet
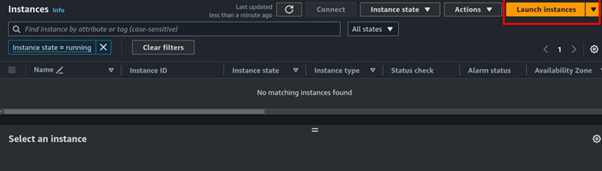
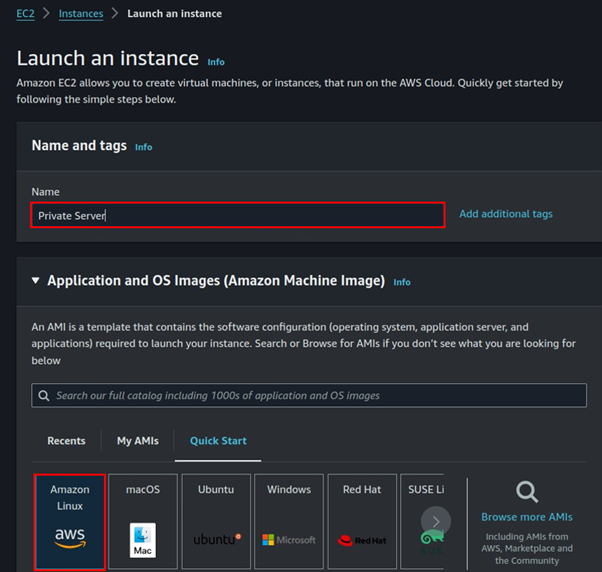
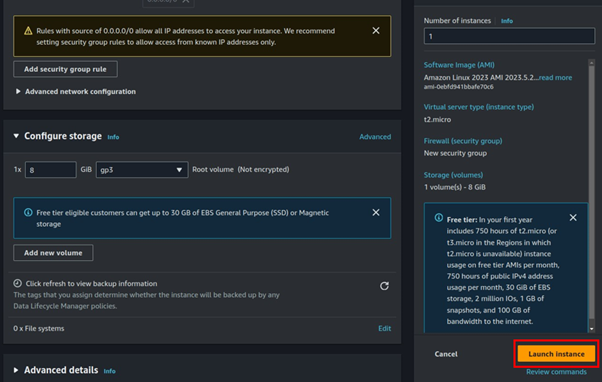
We will begin by launching the private Instance. Navigate to the EC2 console and click Launch Instances.
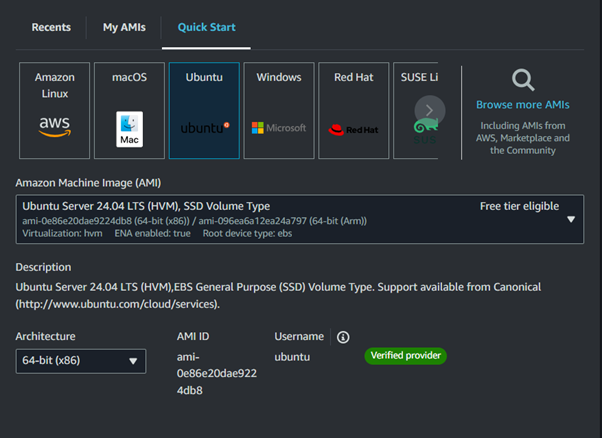
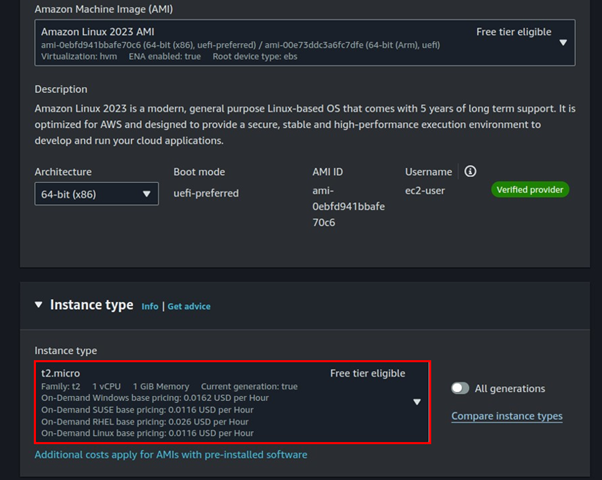
Fill in the Instances details, then for OS select Amazon Linux since it comes with AWS CLI pre-installed.
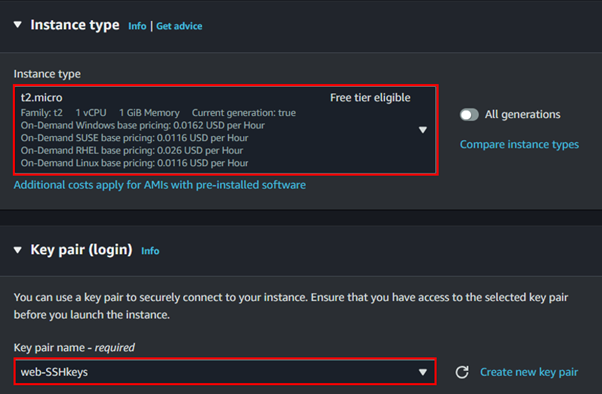
Select t2. Micro instance
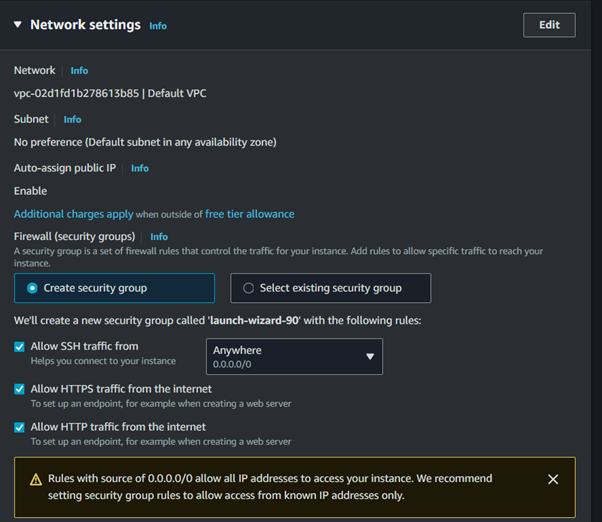
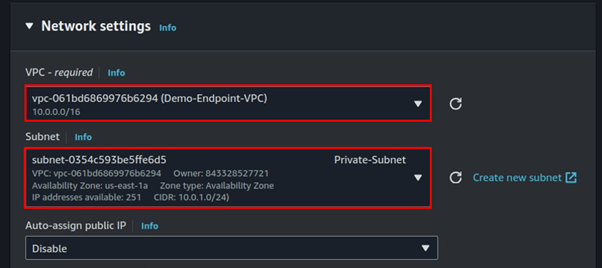
Expand the networking tab, and under VPC select the VPC you just created. Then for subnet select your private subnet.
These are the only settings we need, review under the summary and click Launch Instance.
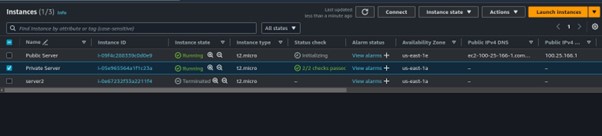
Repeat the same process for the Instance in the public subnet, the only difference is you will select the public subnet under the Networking tab.
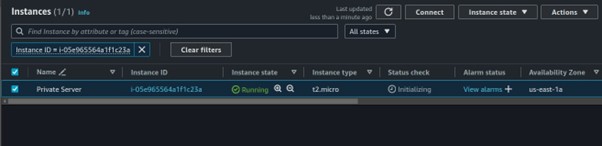
Once the two virtual machines are up and running, connect to your instance in the public subnet.
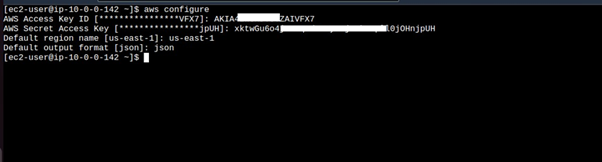
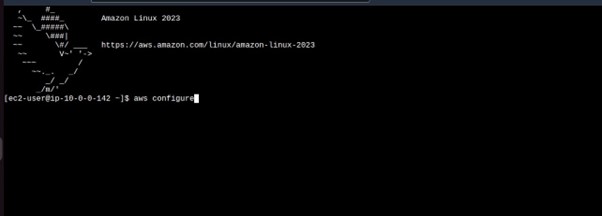
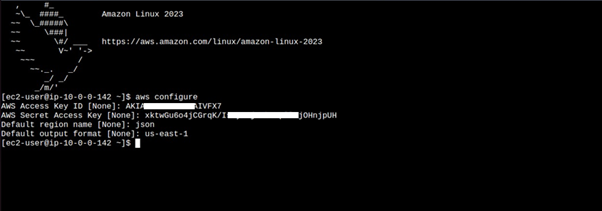
Once in the instance, run the aws configure command, fill in your details.
Once in the instance, run the aws configure command, and fill in your details.
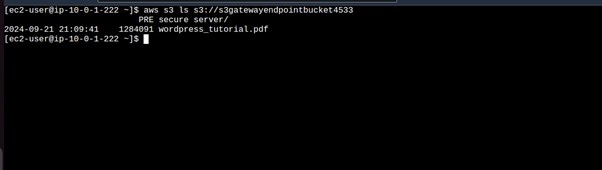
aws s3 ls s3://<bucket-name>
running this command, we can see we can access the contents from our public Instance through the internet.
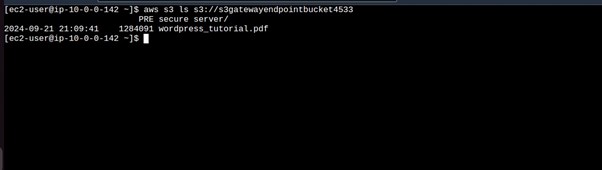
Let’s do the same for our Instance in the private with no internet access. Log in to your instance in the private subnet, you can use the EC2 Instance connect endpoint. Run the aws configure to configure your credentials.
Fill in your key details.
Try listing bucket contents, we can see we are accessing our bucket contents, remember we are now not using the public internet but accessing our bucket securely through our Gateway endpoint. That’s it.
Clean up.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!