Comprehensive Guide to AWS Code Build: Features, Setup, and Best Practices
In modern software development, automating the process of building, testing, and deploying applications is key to streamlining workflows. AWS CodeBuild, part of AWS’s continuous integration and delivery (CI/CD) suite, plays a significant role in automating the build process. It compiles source code, runs tests, and produces deployable software packages in a highly scalable, managed environment so read on as we provide comprehensive guide to AWS Code Build in this blog.
What is AWS CodeBuild?
AWS CodeBuild is a fully managed build service that compiles source code, runs tests, and produces software packages that are ready to deploy. With CodeBuild, you don’t need to worry about provisioning and managing your build infrastructure. You simply provide your build project’s source code and build settings, and CodeBuild handles the rest.
For example, if you have a web application that you want to deploy, you can use CodeBuild to compile your source code, run unit tests, and produce a deployable package. You can also use CodeBuild to build Docker images, run static code analysis, and more. CodeBuild integrates with other AWS services like Code Pipeline, so you can easily automate your entire software release process.
Build Projects and Builds
A build project defines how AWS CodeBuild runs a build. It includes information such as where to get the source code, the build environment to use, the build commands to run, and where to store the build output. A build refers to the process of transforming the source code into executable code by following the instructions defined in the build project.
Key Features of AWS CodeBuild
Automated Builds: Compiles source code and packages it for deployment automatically.
CI/CD Integration: Works seamlessly with AWS CodePipeline to automate your entire CI/CD workflow.
Scalability: Automatically scales to meet the demands of your project, ensuring there are no build queues.
Pay-As-You-Go Pricing: You are only charged for the compute time you use during the build process.
How does AWS CodeBuild Work?
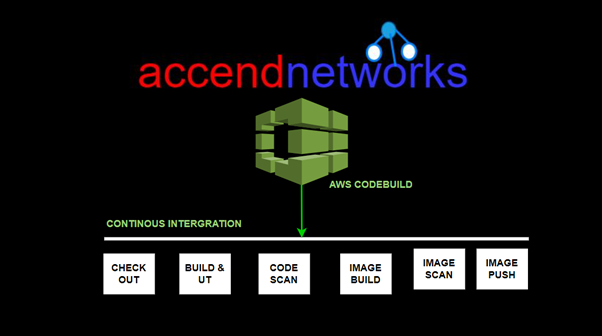
AWS CodeBuild uses a three-step process to build, test, and package source code:
Fetch the source code: CodeBuild can fetch the source code from a variety of sources, including GitHub, Bitbucket, or even Amazon S3.
Run the build: CodeBuild executes the build commands specified in the Buildspec.yaml file. These commands can include compilation, unit testing, and packaging steps.
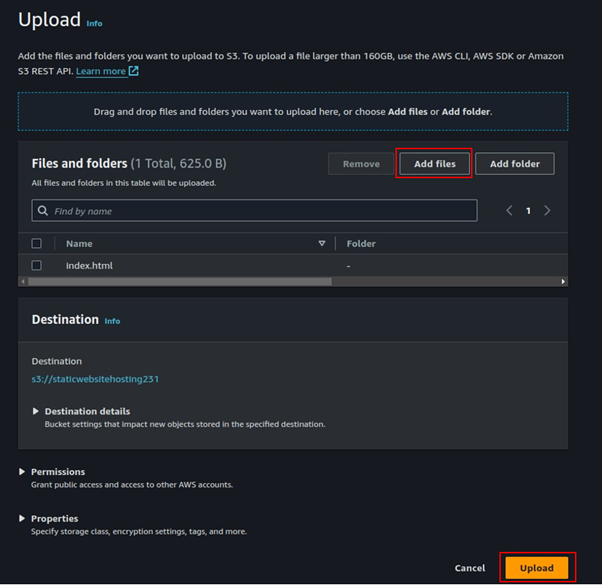
Store build artifacts: Once the build is complete, CodeBuild stores the build artifacts in an Amazon S3 bucket or another specified location. The artifacts can be used for deployment or further processing.
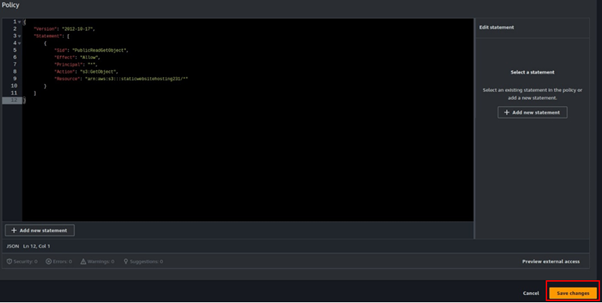
What is the Buildspec.yaml file for Codebuild?
The Buildspec.yaml file is a configuration file used by AWS CodeBuild to define how to build and deploy your application or software project. It is written in YAML format and contains a series of build commands, environment variables, settings, and artifacts that CodeBuild will use during the build process.
Steps to consider when planning a build with AWS CodeBuild
Source Control: Choose your source control system (e.g., GitHub, Bitbucket) and decide how changes in this repository will trigger builds.
Build Specification: Define a buildspec.yml file for CodeBuild, specifying the build commands, environment variables, and output artifacts.
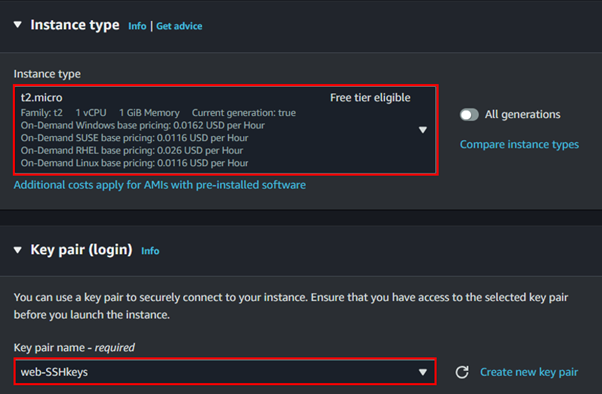
Environment: Select the appropriate build environment. AWS CodeBuild provides prepackaged build environments for popular programming languages and allows you to customize environments to suit your needs.
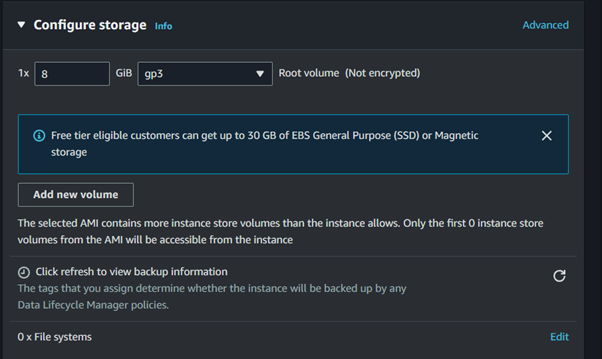
Artifacts Storage: Decide where the build artifacts will be stored, typically in Amazon S3, for subsequent deployment or further processing.
Build Triggers and Rules: Configure build triggers in CodePipeline to automate the build process in response to code changes or on a schedule.
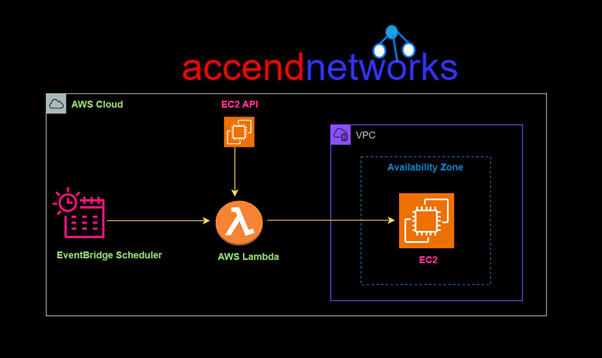
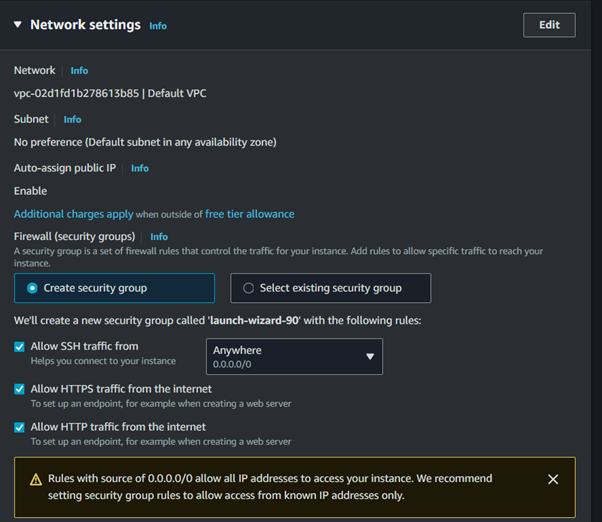
VPC: Integrating AWS CodeBuild with Amazon Virtual Private Cloud (VPC) allows you to build and test your applications within a private network, which can access resources within your VPC without exposing them to the public internet.
Conclusion:
AWS CodeBuild is an excellent solution for developers and DevOps teams looking to automate the build process in a scalable, cost-effective manner. Whether you’re managing a small project or handling complex builds across multiple environments, AWS CodeBuild ensures that your software is always built and tested with the latest code changes.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!