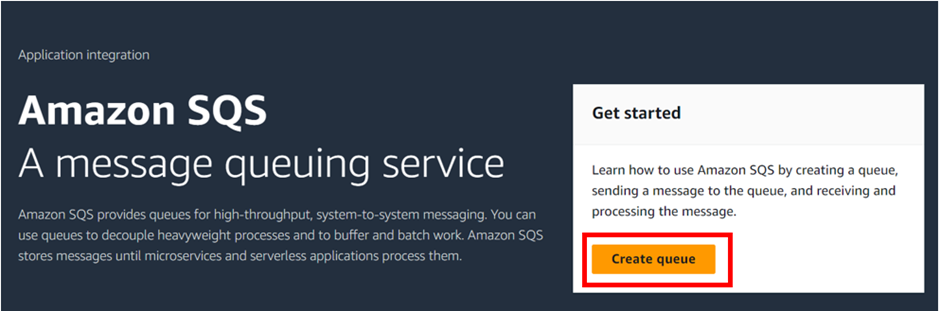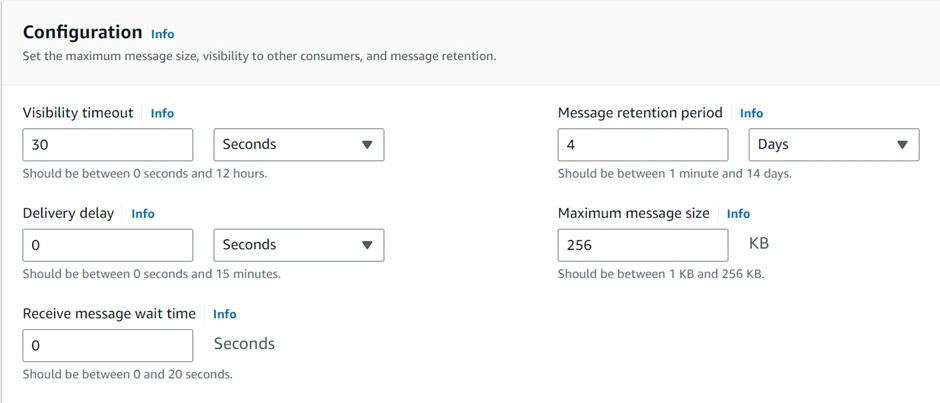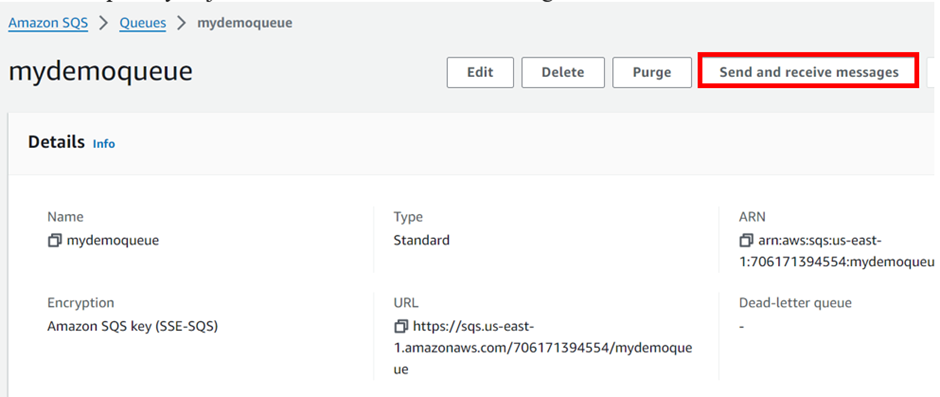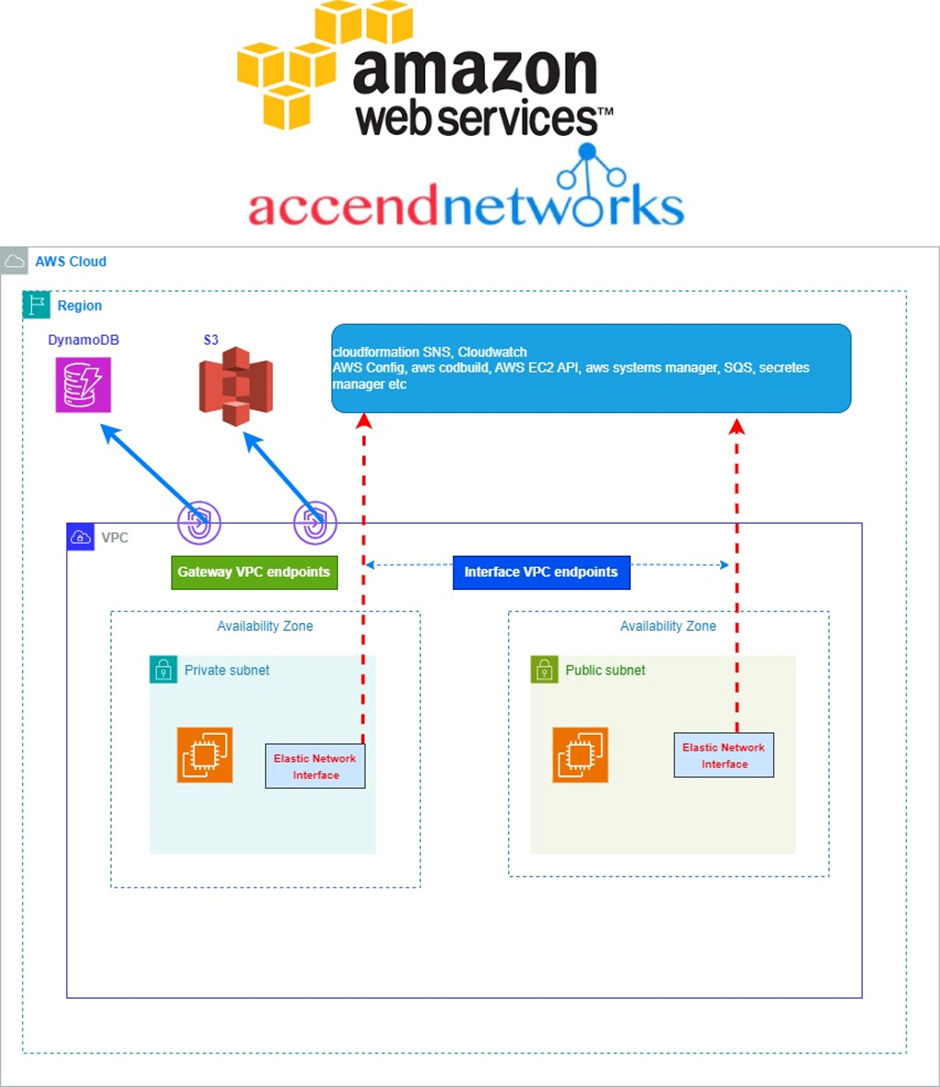
Find Out What Decoupling Workflows in AWS Is
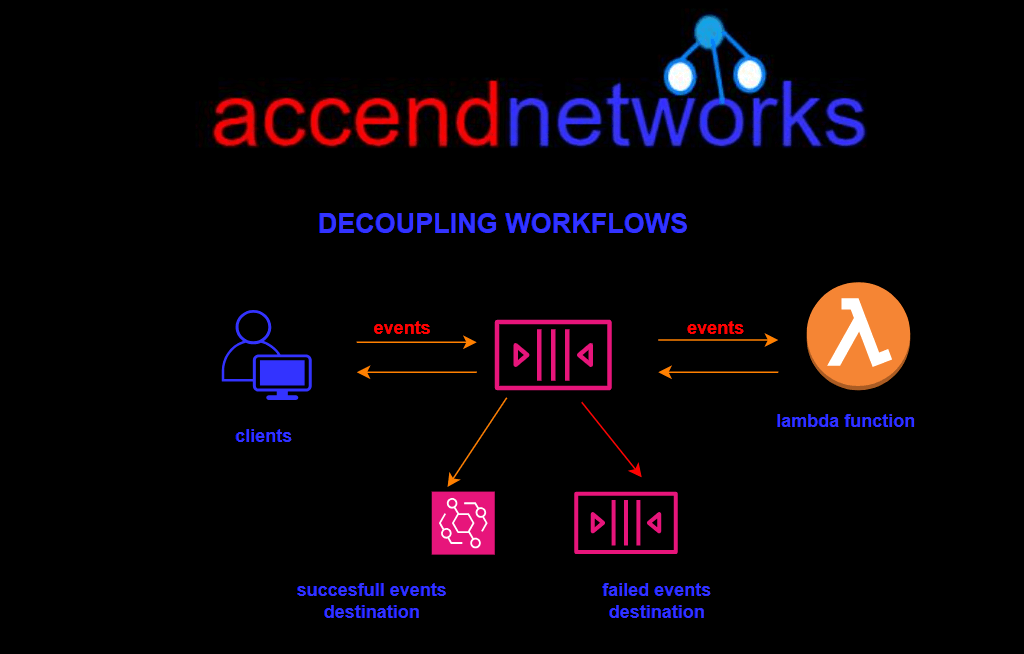
Decoupling workflows involves breaking down the components of a system into loosely connected modules that can operate independently. This not only enhances scalability and flexibility but also improves fault tolerance, as failures in one component do not necessarily impact the entire system. AWS provides a variety of services that facilitate decoupling, such as AWS Simple Queue Service (SQS), AWS Simple Notification Service (SNS), and AWS Step Functions.
To explain this, we will use this scenario.
Direct Integration in Application Components
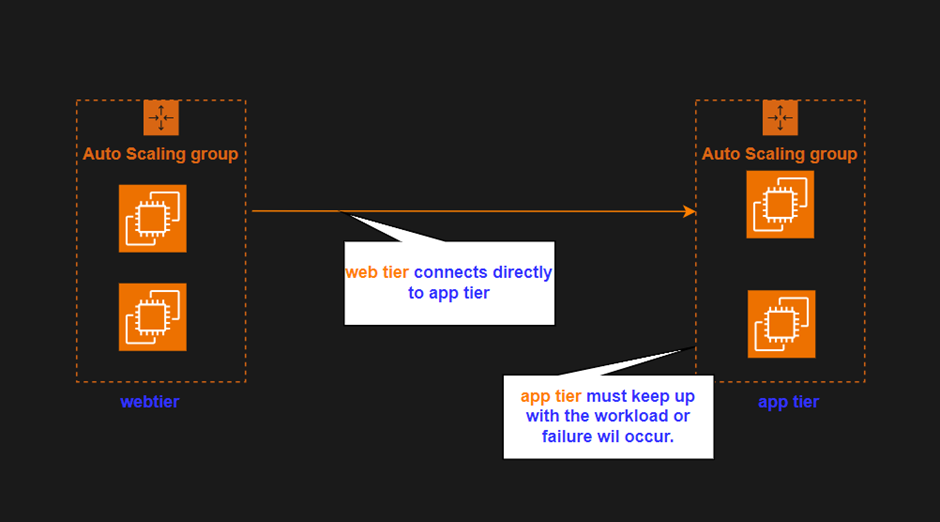
In a direct integration scenario, the web tier and the app tier are connected without intermediary components. This approach does come with lots of challenges.
One significant drawback arises when the app tier is required to keep pace with the incoming workload. In the event of a sudden surge in demand, such as an influx of customer orders, the app tier must be capable of scaling up rapidly to handle the increased load. This real-time scalability requirement is essential to prevent any system failures and ensure a seamless customer experience.
We can use auto-scaling mechanisms in such scenarios. Auto-scaling, although efficient, involves the automatic launch of instances to meet the rising demand. However, the time taken for these instances to become operational may introduce delays, potentially leading to the loss of critical information. In the context of customer orders, this delay could result in a lost customer order.
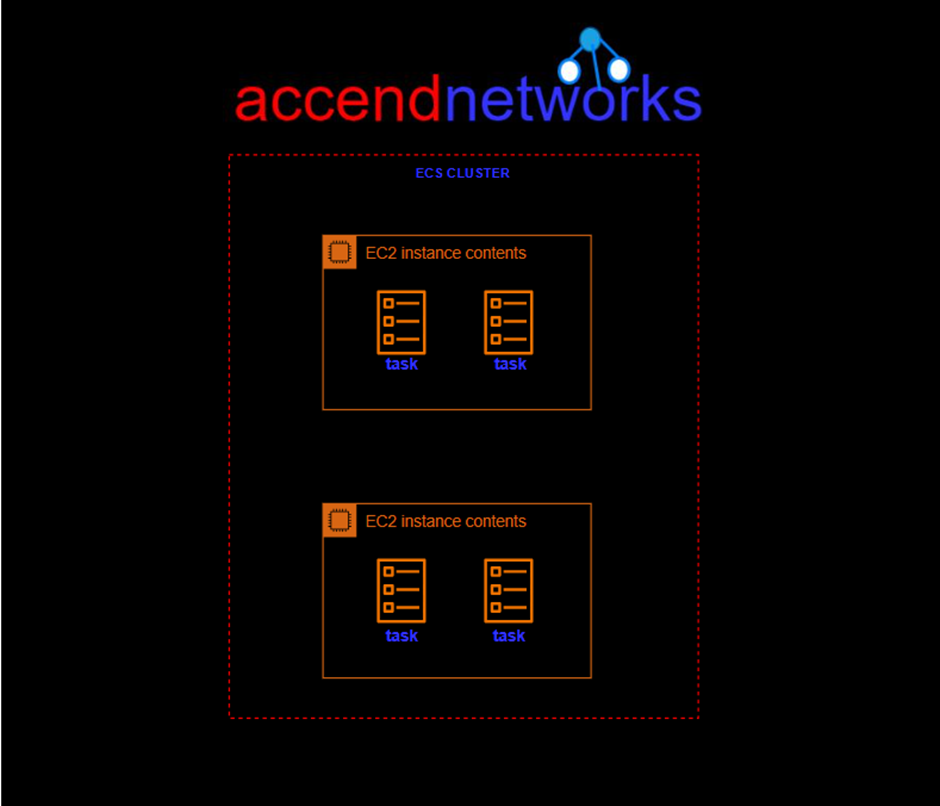
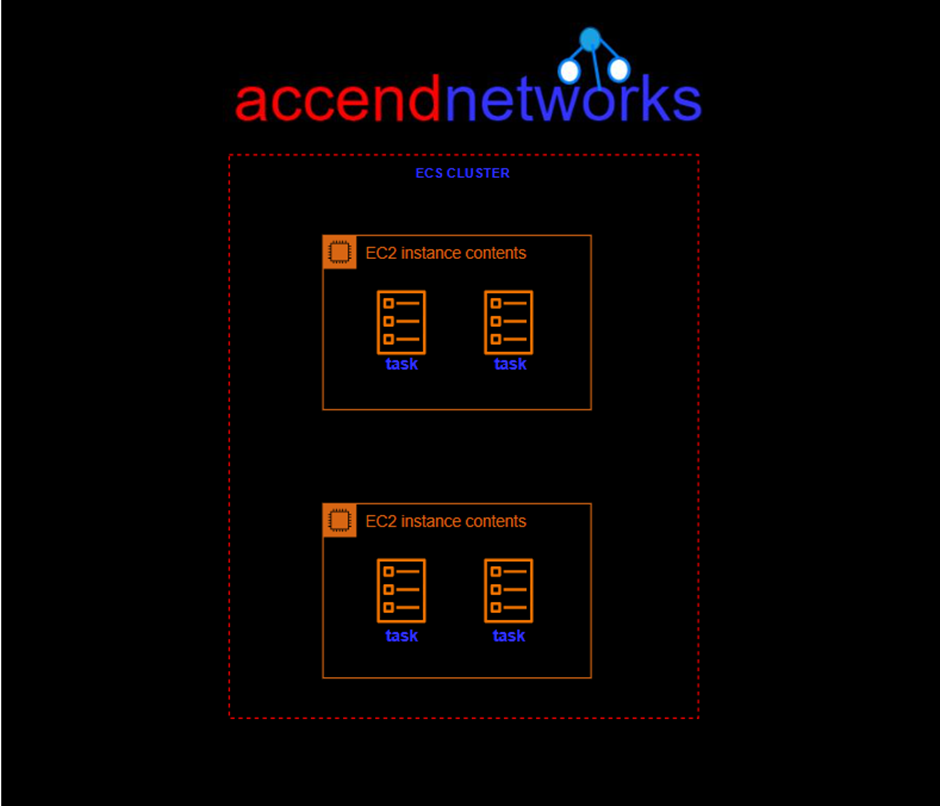
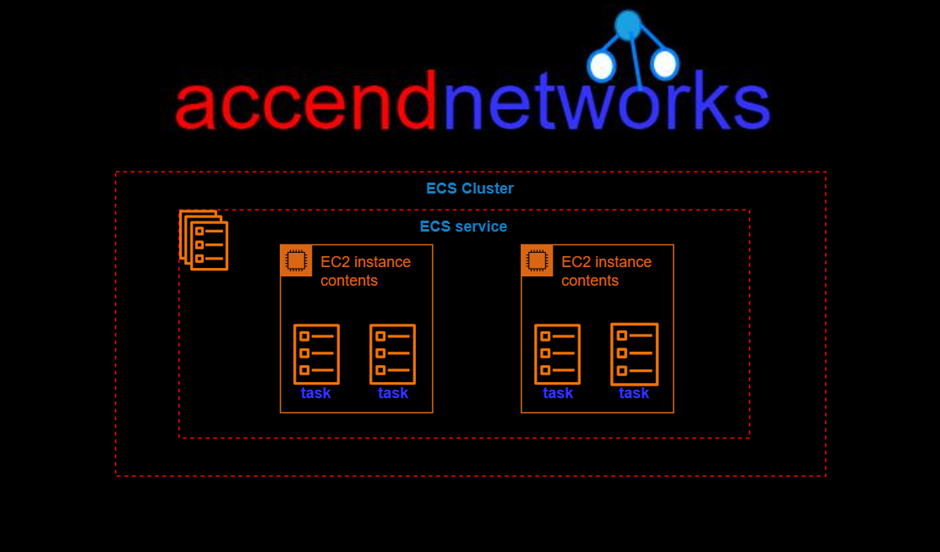
Decoupled Workflows
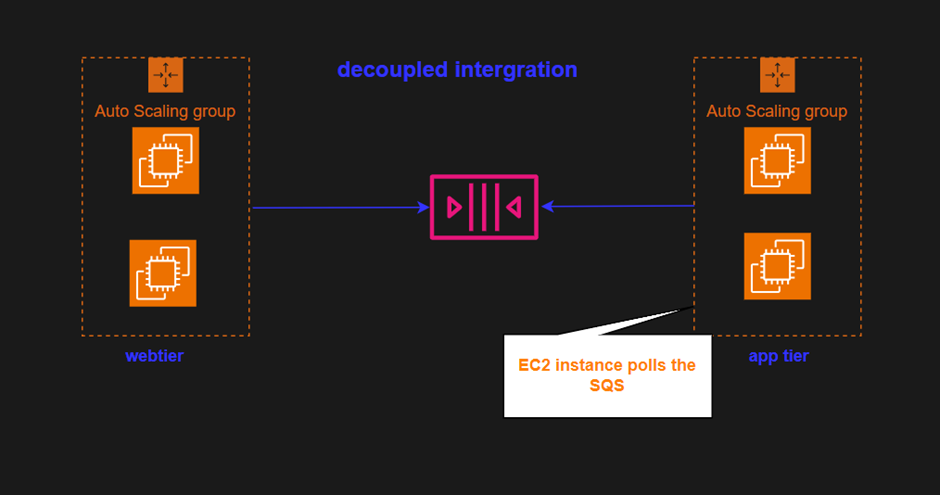
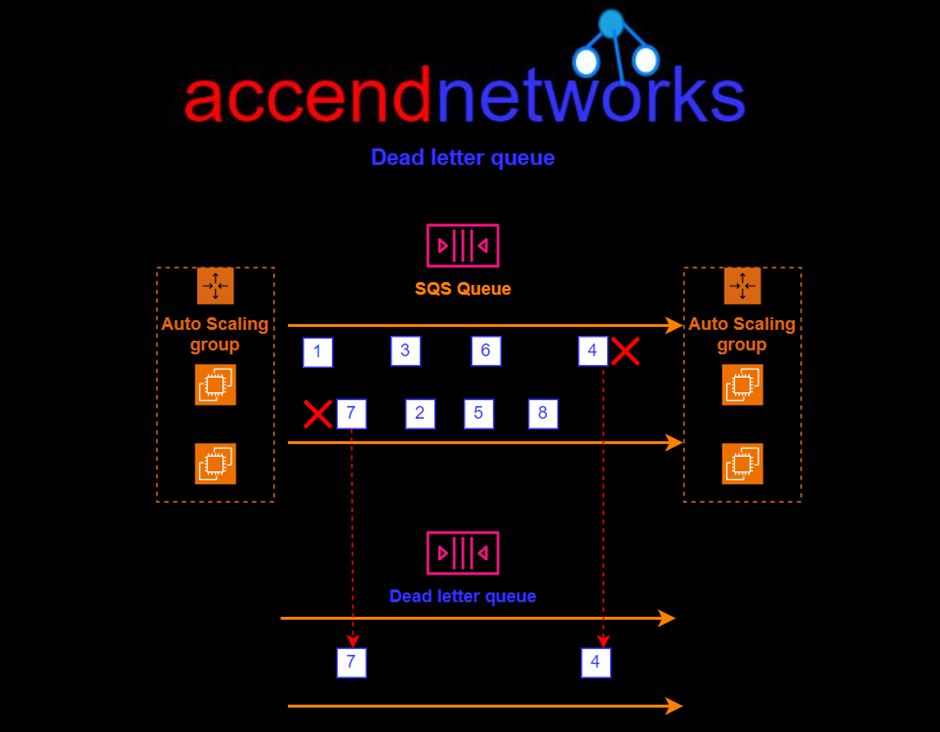
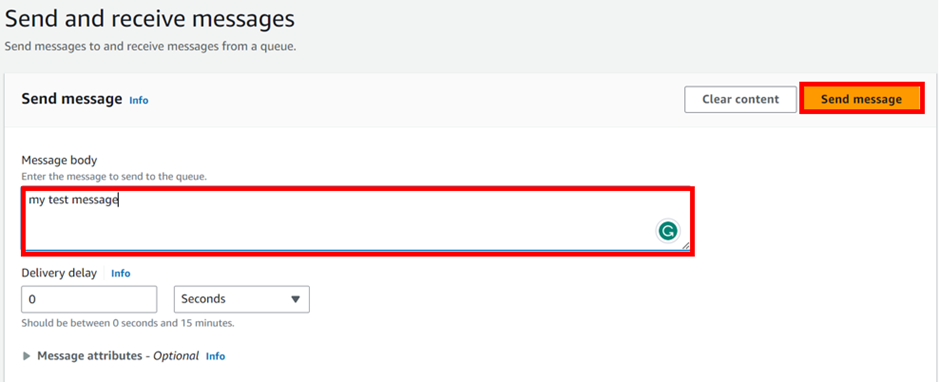
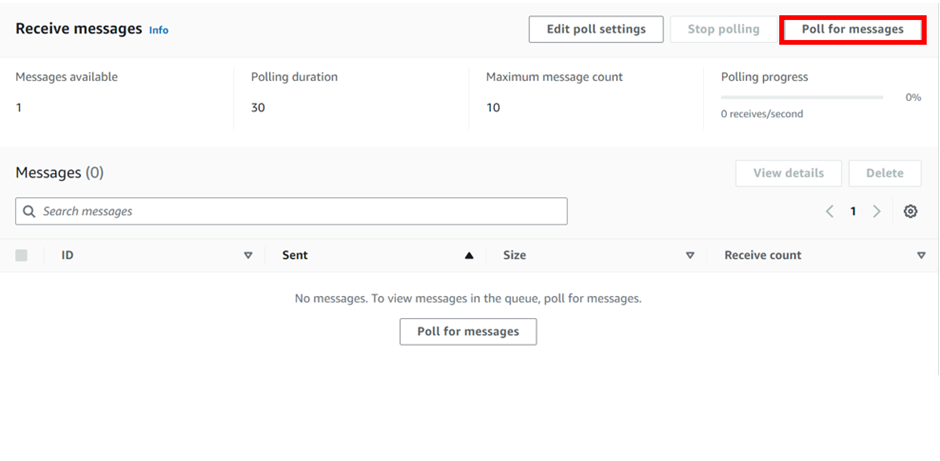
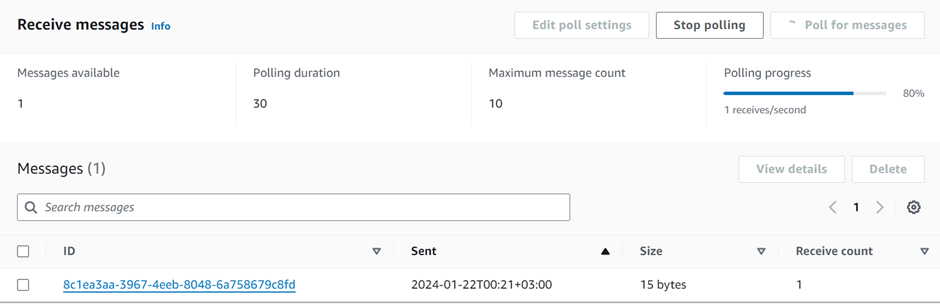
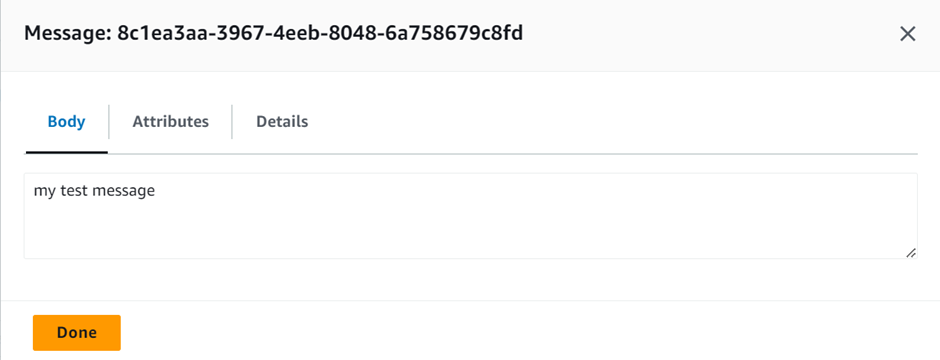
Instead of having the web tier and the app tier directly connected, we’ll put an SQS queue in the middle.
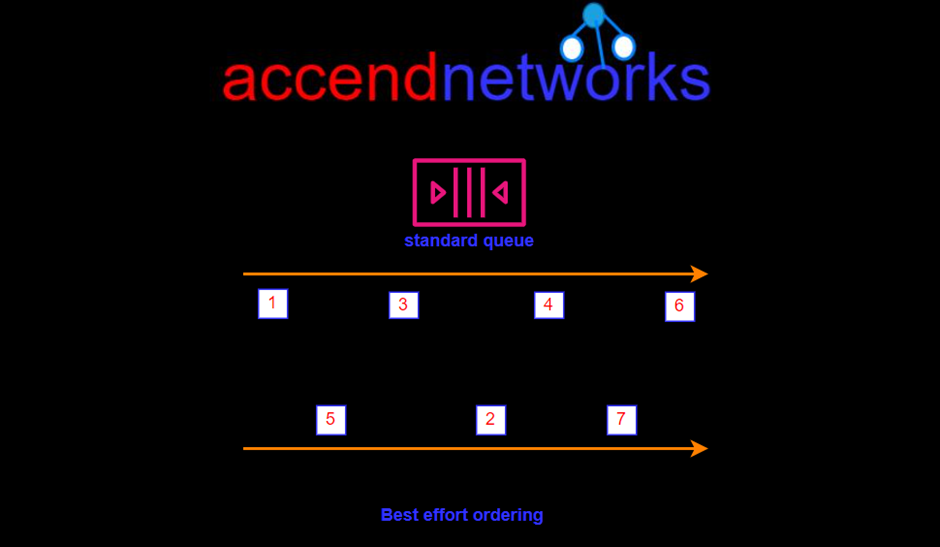
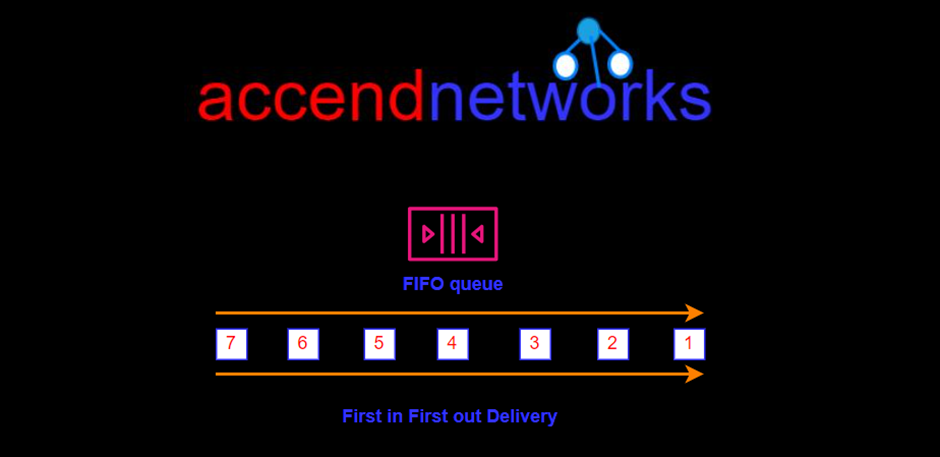
The web tier now talks to the queue and puts in orders as messages. The app tier, on the other hand, keeps an eye on the queue by checking if there are any messages to be processed. If there’s a sudden flood of orders, the queue can handle it easily. More orders just wait in the queue until the app tier is ready to process them. hence, no stress of the app tier keeping up with all the workloads at once. if there is a sudden huge amount of information coming in and lots of orders being placed, then the queue can scale very easily. So, we’ll just end up with a lot more orders in the queue awaiting processing. The app tier may need to scale but it doesn’t have the issue of direct integration where the orders might be lost because they can sit in the queue for quite a bit of time and the app tier can process them as soon as it’s ready.
We can also see decoupling in Lambda invocations where we have synchronous and synchronous invocation of Lambda functions.
When you invoke a function synchronously, Lambda runs the function and waits for a response. With this model, there are no built-in retries. You must manage your retry strategy within your application code.
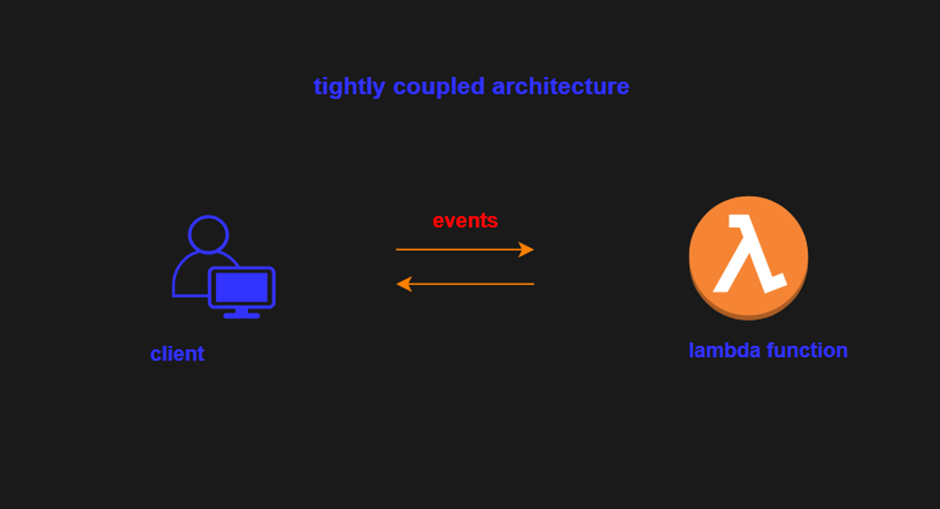
On the other hand, by decoupling lambda functions, and using a synchronous invocation, we see lots of added advantages, as our Lambda function must not keep up with the surge of events but just poll the queue.
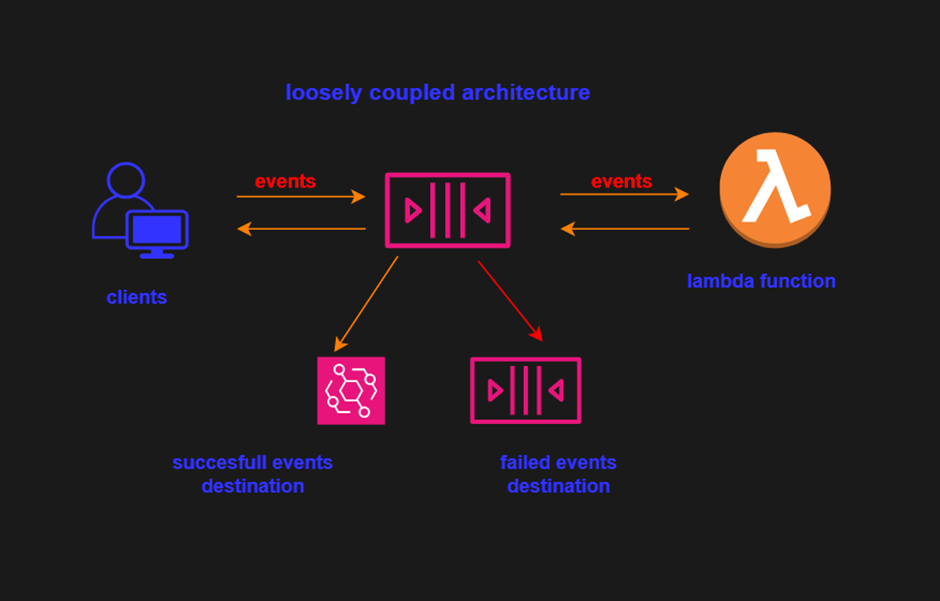
Benefits of Decoupling Workflows on AWS Cloud
Conclusion
Stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!