


Accend Networks San Francisco Bay Area Full Service IT Consulting Company
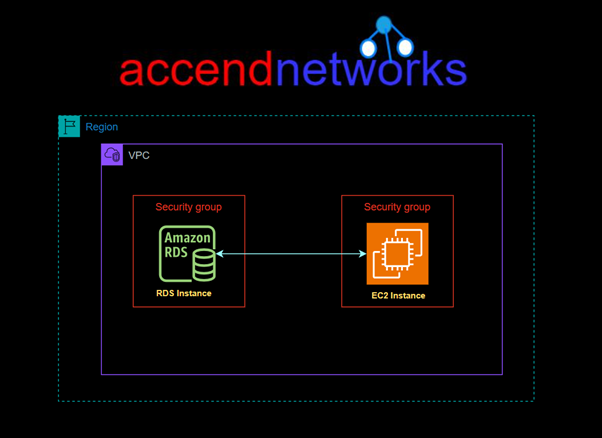
Amazon Web Services (AWS) provides various tools to simplify the management of web applications, including Amazon RDS (Relational Database Service) and EC2 instances. Amazon RDS is a fully managed service that allows users to set up, operate, and scale relational databases in the cloud. At the same time, EC2 (Elastic Compute Cloud) provides secure and scalable computing power. Connecting these two services is essential for applications requiring database backends for dynamic data storage.
In this hands-on guide, we’ll walk you through connecting an EC2 instance with Amazon RDS, covering essential configurations, security, and best practices.
For this project, I have an EC2 Instance already launched and running. To launch an EC2 instance, you can follow these steps.
Go to the EC2 Dashboard: Open the EC2 dashboard and select “Launch instance.”
Choose an Amazon Machine Image (AMI): Select an OS that suits your application environment, such as Amazon Linux or Ubuntu.
Select an Instance Type: Choose a size based on your application needs, considering the expected database connection load.
Configure Network and Security Settings:
Ensure the instance is in the same VPC as the RDS instance to avoid connectivity issues.
Assign a Security Group to the EC2 instance that allows outbound traffic on the port your RDS instance uses, port 3306.
Launch the Instance: Once configured, launch the instance and connect to it using SSH.
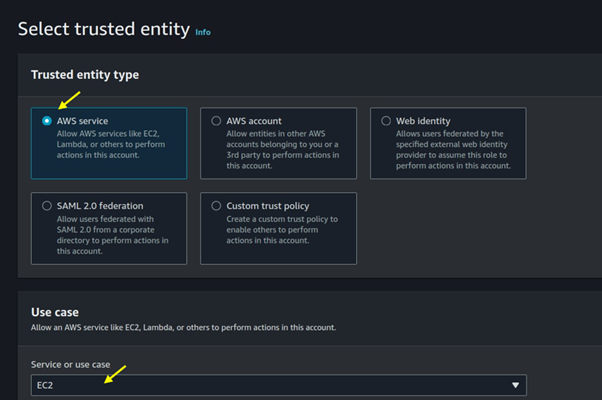
Let’s configure the IAM Role:
Go to the I AM console and search for I AM then select I AM under services.
In the I AM dashboard, select roles then click on the create role button.
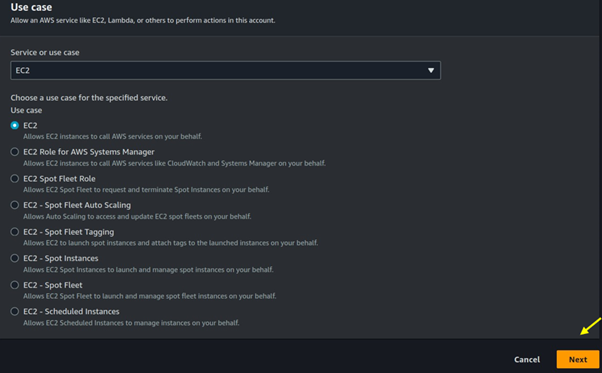
Under trusted entity select AWS service then use case select EC2, then scroll sown and click on the next button.
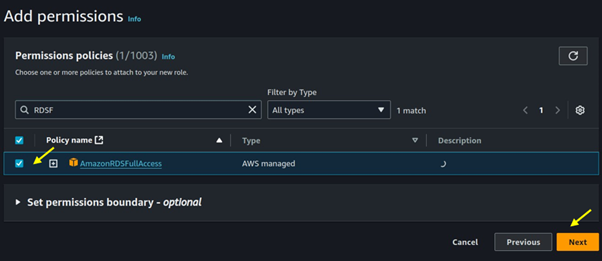
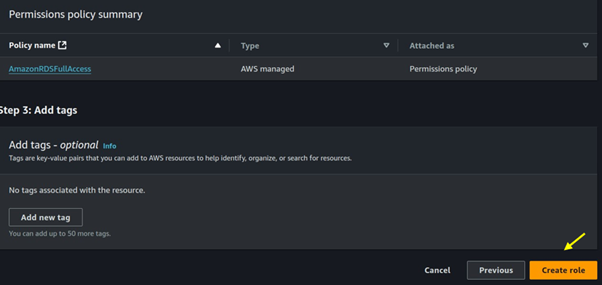
For permission select RDS full access, then click next.
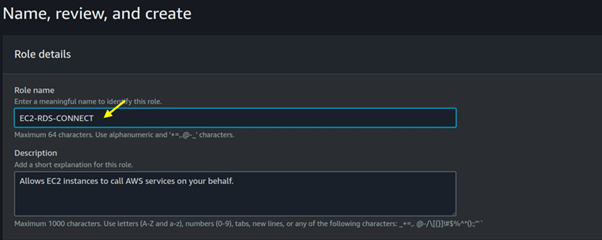
Name your role then click on the Create role.
Come back to your EC2 instance and then attach that role.
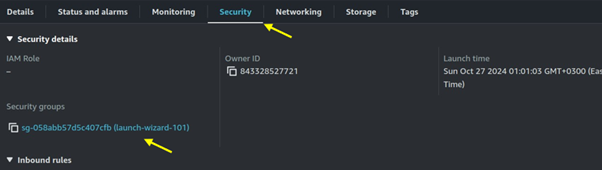
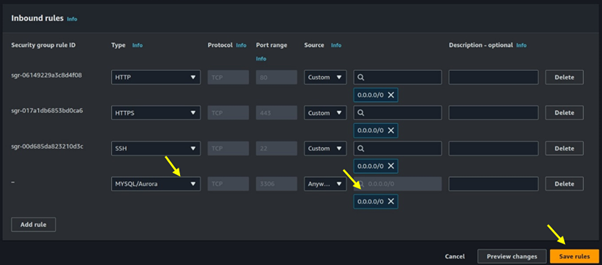
Since RDS listens on port 3306, we will open port 3306 in the security groups of our EC2 instance. Move to the security tab of your EC2 instance then click on the security group wizard.
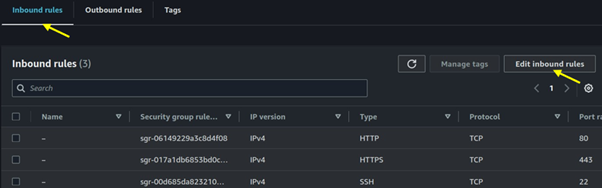
Move to the inbound rules tab then click on edit inbound rules.
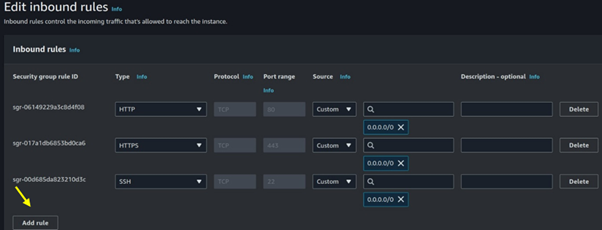
Click add rule.
Select MYSQL/Aurora then for destination select 0.0.0.0/0 then click on save.
Set Up Amazon RDS
Navigate to the RDS console.
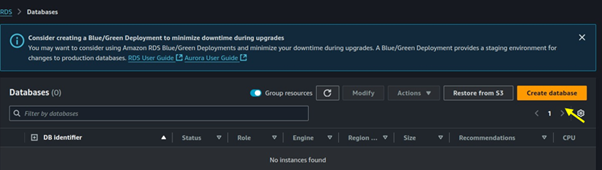
Click on DB instances then click on the Create database.
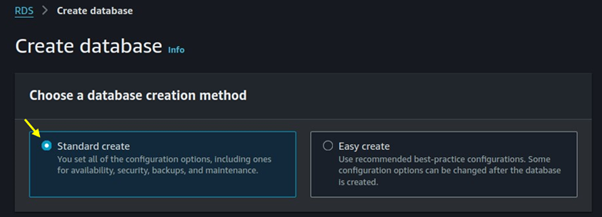
Choose standard create as the creation method.
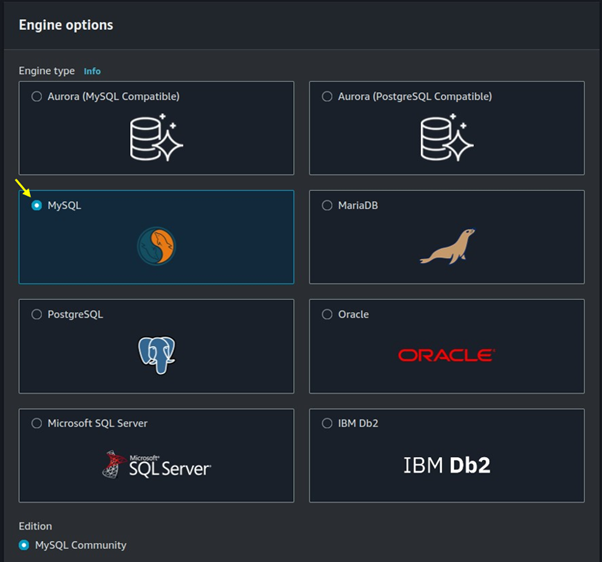
Choose MySQL as the DB engine type.
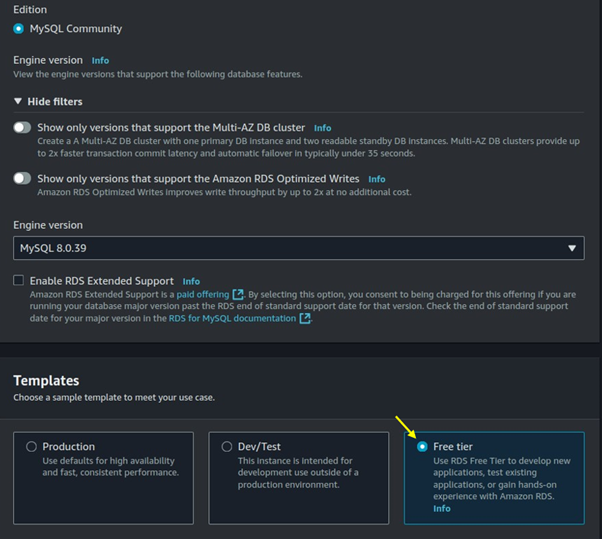
Move with the default Engine version then for templates select the free tier.
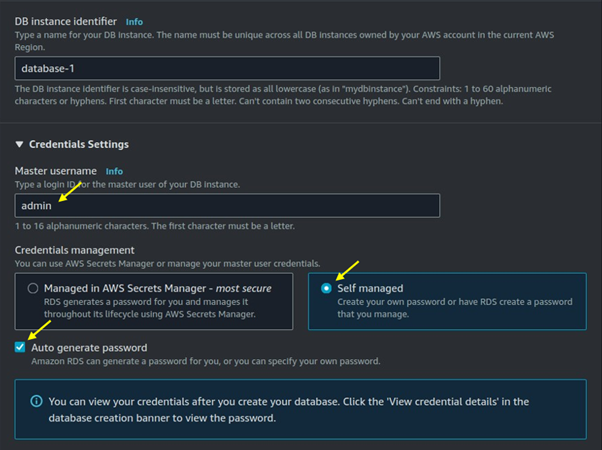
Under credentials settings choose the master username for your DB, then select self-managed. You can generate your password or choose an autogenerated password.
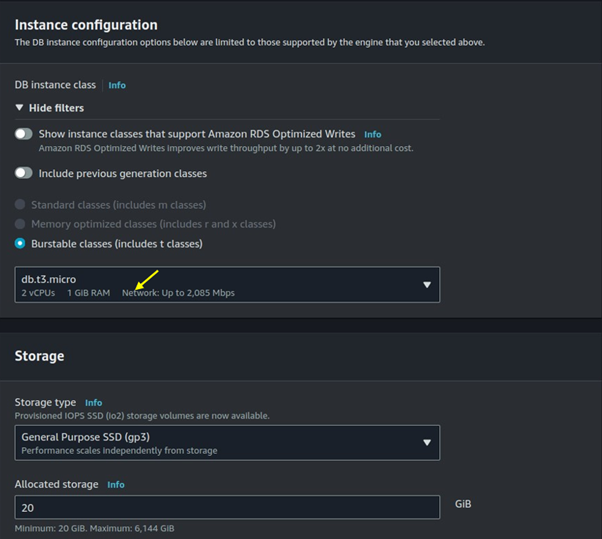
Under burstable classes, choose on dB t3. Micro then leaves storage as default.
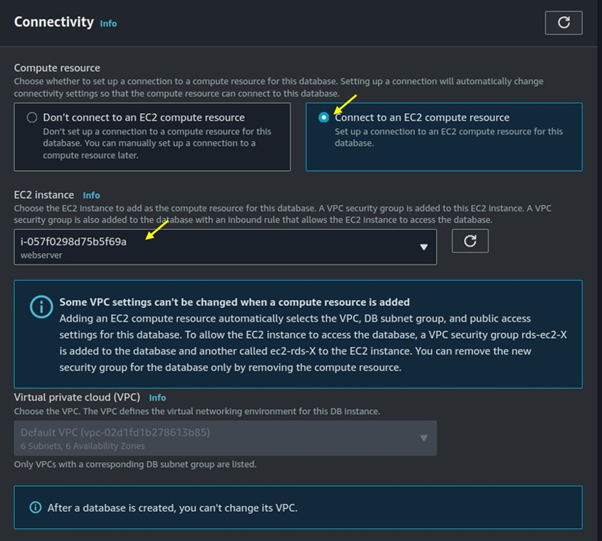
For connectivity select connect to an EC2 compute resource. Under EC2 instance select the drop-down button then select the EC2 instances you created.
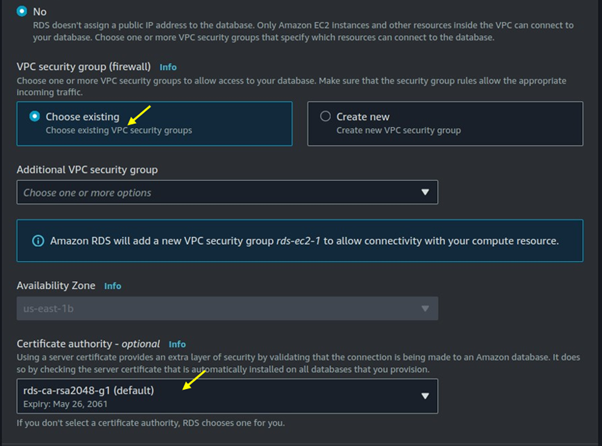
Under the VPC security firewall choose existing.
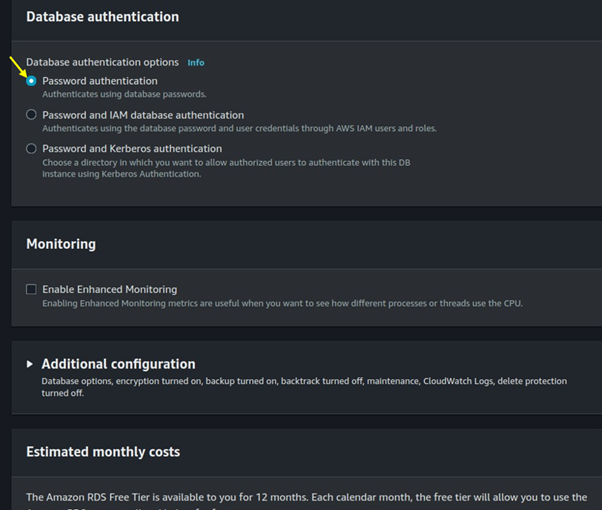
For database authentication, choose a password.
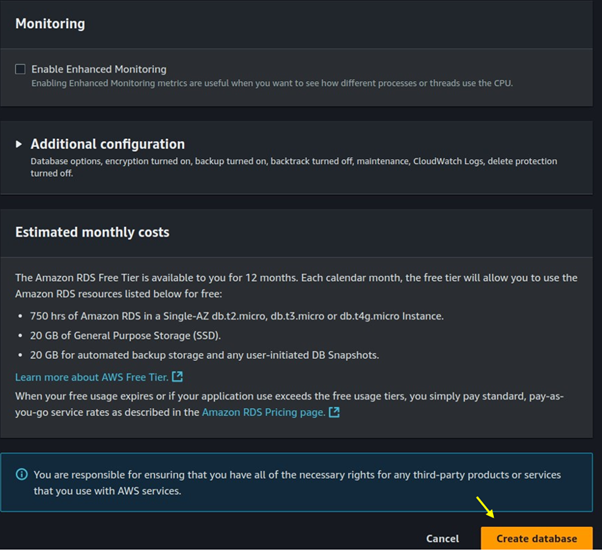
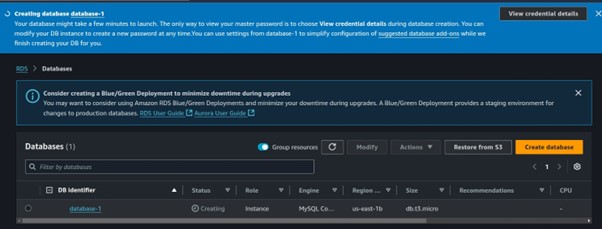
Scroll down and click on Create Database.
Database creation has been initiated.
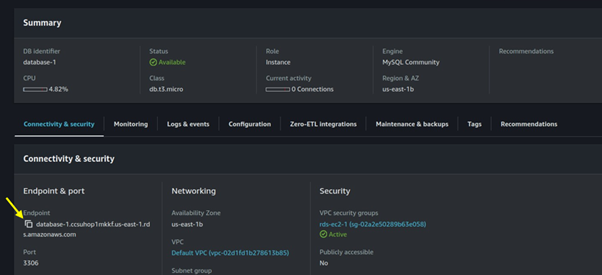
Click on the created database and copy the Database endpoint to your clipboard. Since we will need this for connecting to the database.
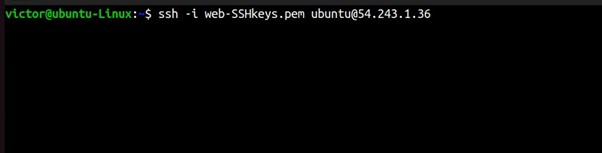
Now SSH into your EC2 instance.
Run this code to install the MySQL client.
sudo apt update
sudo apt install mysql-client -y
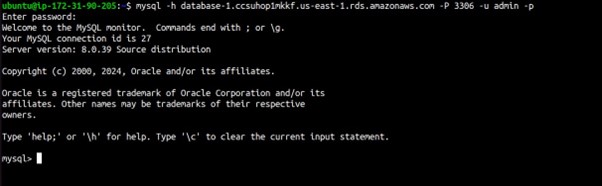
Now that the client software is installed, you can connect to your RDS instance.
mysql -h [RDS_ENDPOINT] -P [PORT] -u [USERNAME] -p
show databases;
Able to connect, thumps up.
Best Practices
Use IAM Authentication: For added security, enable IAM database authentication and manage access via AWS Identity and Access Management.
Enable Encryption: Encrypt the database at rest and enable SSL for in-transit data encryption.
Implement Monitoring and Logging: Use Amazon CloudWatch to monitor the database performance, and set up alerts for any unusual activity.
Maintain Security Groups: Review and tighten Security Group rules regularly to prevent unauthorized access.
Automate Backups: Configure automated backups for data recovery in case of data loss.
Conclusion
Connecting Amazon RDS with an EC2 instance involves careful configuration of network settings, security groups, and database settings. By following these steps, you’ll establish a secure and reliable connection between your EC2 instance and Amazon RDS, supporting scalable and highly available database access for your applications.
Thanks for reading and stay tuned for more. Make sure you clean up.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!
As more companies adopt containerization, the importance of strong container management tools grows. Amazon Elastic Kubernetes Service (EKS) is a helpful tool for running Kubernetes clusters on AWS. It offers a managed service that makes it easier to deploy, scale, and manage containerized applications. In this blog, we’ll look at the features of Amazon EKS and its benefits compared to other container management solutions.
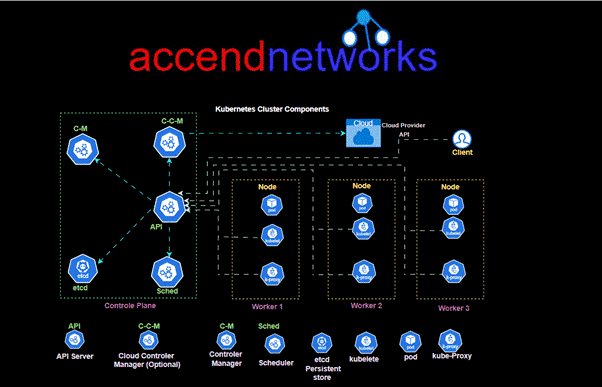
The above Kubernetes architecture consists of a master node (control plane) and multiple worker nodes, creating a robust system for orchestrating containerized applications. The control plane manages the cluster and includes components like the API Server, which is the central hub for all communication; etcd, a distributed key-value store that keeps configuration data and state; Controller Manager, which enforces the desired state by managing replicas and handling failures; and Scheduler, which assigns pods to nodes based on resource availability. Worker nodes host containers, managed by kubelet (which ensures that containers are running) and kube-proxy (which manages networking
Amazon EKS is a managed Kubernetes service that allows you to run Kubernetes clusters on AWS without the complexity of managing the Kubernetes control plane. Kubernetes itself is an open-source system for automating the deployment, scaling, and management of containerized applications, primarily using Docker. EKS abstracts much of the complexity associated with setting up and maintaining a Kubernetes environment, enabling developers to focus on building applications rather than managing infrastructure.
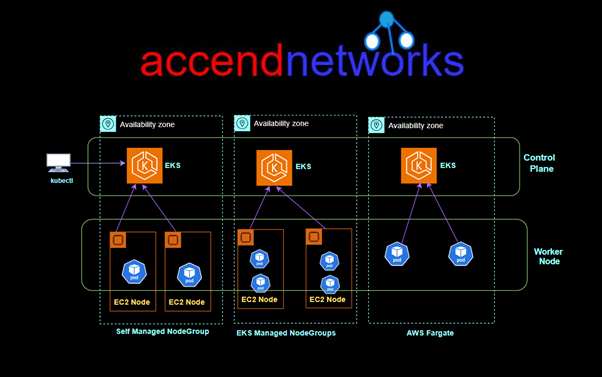
Amazon EKS provides a scalable, highly available control plane for Kubernetes workloads. When you run applications on Amazon EKS, as with Amazon ECS, you can choose to provide the underlying compute power for your containers with Amazon EC2 instances or with AWS Fargate.
While both Amazon EKS and Amazon Elastic Container Service (ECS) are designed to manage containerized applications, they cater to different user needs:
Both services aim to achieve similar goals, but the choice between EKS and ECS often depends on existing infrastructure and expertise within the organization.
EKS supports two primary deployment models for worker nodes:
EC2 Worker Nodes
For a serverless container option, EKS integrates with AWS Fargate, allowing you to run containers without managing EC2 instances. With AWS Fargate, there’s no need for infrastructure management; you simply specify the required CPU and memory, and Fargate handles the rest.
Data Volumes in EKS
When working with persistent data in EKS, specifying storage classes that define types of storage is crucial. EKS supports several AWS storage solutions:
Use Cases for Amazon EKS
Amazon EKS is particularly beneficial for organizations that:
Conclusion
Amazon EKS is a powerful tool for setting up and managing Kubernetes clusters on AWS. It includes features such as managed node groups, serverless containers using Fargate, and a wide range of AWS storage options. EKS makes managing Kubernetes easier while offering the scalability and flexibility that modern apps need.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!

The AWS Command Line Interface (CLI)is a powerful tool that allows developers and system administrators to manage their AWS services directly from the command line. This blog will walk you through the process of configuring AWS effectively, providing you with the knowledge and best practices to make the most of this essential tool.
The AWS CLI is a unified tool that provides a consistent interface for interacting with AWS services. With the AWS CLI, you can automate tasks, manage resources, and execute commands without having to navigate through the AWS Management Console.
Step 1: Install AWS CLI
Below are step-by-step instructions to configure the AWS CLI on your local machine or an EC2 instance and run multiple commands:
Make sure you have an Instance running, you can as well do this on your local machine.
Install AWS CLI
Ensure that you have the AWS CLI installed on your local machine. You can download and install it from the official AWS CLI download page.
Step 2: Open a Terminal or Command Prompt
Open your terminal.
In the terminal, run the following command:
aws configure
Enter AWS Access Key ID
Enter the AWS Access Key ID associated with your IAM user.
Enter the AWS Secret Access Key
Enter the AWS Secret Access Key associated with your IAM user.
Set Default Region
Enter the default region you want to use.
Set Output Format
Choose the default output format.
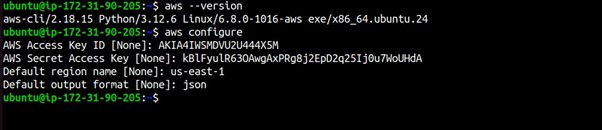
Example Interaction:
AWS Access Key ID [None]: YOUR_ACCESS_KEY_ID
AWS Secret Access Key [None]: YOUR_SECRET_ACCESS_KEY
Default region name [None]: us-central-1
Default output format [None]: json
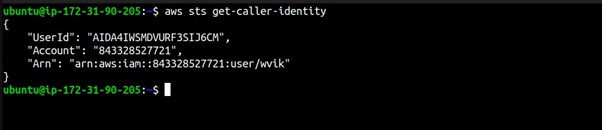
To ensure that your AWS CLI configuration is set up correctly, you can run a simple command to check your credentials:
aws sts get-caller-identity
This command should return details about your AWS account and confirm that your CLI is configured correctly.
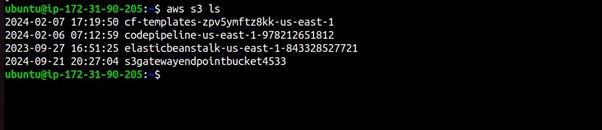
Run AWS CLI Commands
Example 1: List S3 Buckets
aws s3 ls
This command will list the S3 buckets in your AWS account.
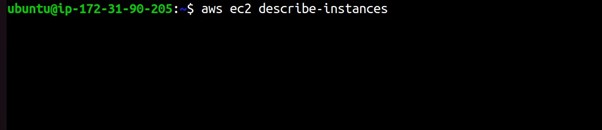
Example 2: Describe EC2 Instances
aws ec2 describe-instances
This command will describe your EC2 instances in the default region.
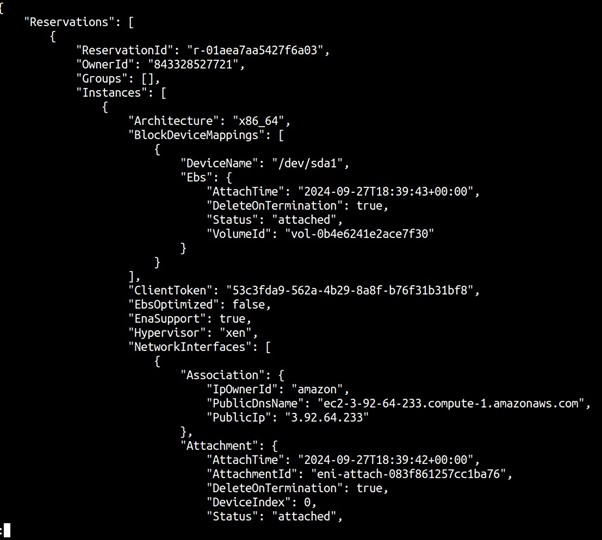
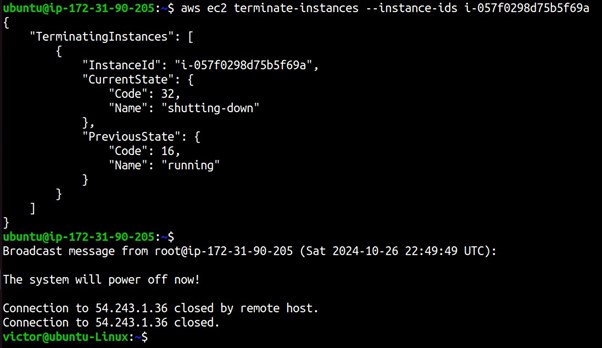
You can also run the CLI command to terminate your EC2 instance as shown below.

Use IAM Roles: Instead of using long-term access keys, consider using IAM roles for enhanced security, especially if you’re running CLI commands from EC2 instances.
Utilize Profiles: If you manage multiple AWS accounts, create separate profiles for each account by using the –profile flag during configuration:
Copy code
aws configure –profile myprofile
Environment Variables: You can also set environment variables for your AWS credentials. This is useful for CI/CD pipelines or automation scripts.
Troubleshooting AWS CLI Configuration Issues
If you encounter issues while using AWS CLI, consider the following troubleshooting tips:
Check Credentials: Ensure that your AWS Access Key ID and Secret Access Key are correct and have the necessary permissions.
Validate Region: Make sure that the region specified in your configuration is correct and that the services you are trying to access are available in that region.
Session Expiry: If you’re using temporary credentials, be aware that they expire after a certain duration. Refresh your credentials if necessary.
Conclusion
Configuring AWS CLI is a straightforward process that empowers you to manage AWS services efficiently from the command line. By following this step-by-step guide, you can set up AWS CLI, verify your configuration, and implement best practices to enhance your cloud management capabilities.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!
Deploying web applications in the cloud can be complicated, especially for teams that don’t have a lot of experience with cloud infrastructure. AWS App Runner helps with this by offering a fully managed service that lets you deploy web applications and APIs directly from your source code or a container image. In this article, we’ll look at how AWS App Runner makes deployment easier and discuss its main features.
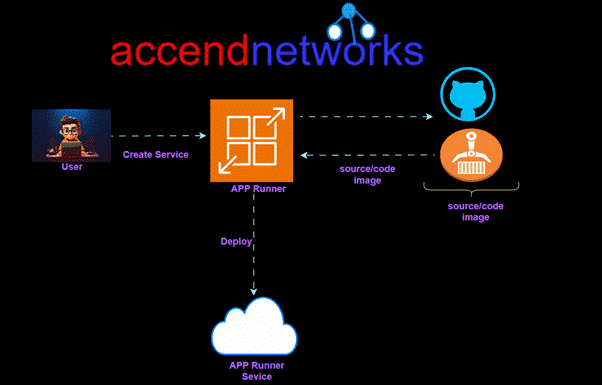
AWS App Runner is an AWS service that provides a fast, simple, and cost-effective way to deploy from source code or a container image directly to a scalable and secure web application in the AWS Cloud. You don’t need to learn new technologies, decide which compute service to use, or know how to provision and configure AWS resources.
AWS App Runner connects directly to your code or image repository. It provides an automatic integration and delivery pipeline with fully managed operations, high performance, scalability, and security.
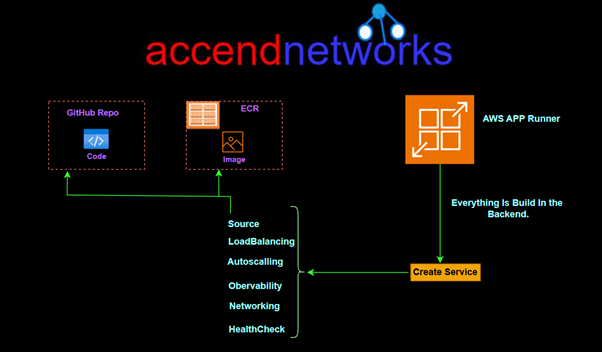
AWS App Runner supports two main deployment methods:
App Runner provides a cost-effective way to run your application. You only pay for resources that your App Runner service consumes. Your service scales down to fewer compute instances when request traffic is lower. You have control over scalability settings: the lowest and highest number of provisioned instances, and the highest load an instance handles.
If you’re a developer, you can use App Runner to simplify the process of deploying a new version of your code or image repository.
For operations teams, App Runner enables automatic deployments each time a commit is pushed to the code repository or a new container image version is pushed to the image repository.
AWS App Runner is ideal for a range of scenarios, including:
AWS App Runner vs. Other AWS Services
AWS offers other services for deploying containerized applications, such as Amazon Elastic Kubernetes Service (EKS) and Amazon Elastic Container Service (ECS). However, App Runner differs by focusing on simplicity and managed deployments. Here’s a quick comparison:
Conclusion
AWS App Runner simplifies web application deployment by handling infrastructure, scaling, and security, making it easier than ever to deploy applications on AWS. Whether you’re a startup, a developer, or a team seeking an efficient way to deploy containerized applications without managing infrastructure, App Runner offers a robust, cost-effective solution.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!

Amazon DynamoDB is a strong, fully managed NoSQL database that can grow quickly and adapt easily. But when dealing with high-traffic applications or high latency workloads, even the best databases can improve with caching. This is where DynamoDB Accelerator (DAX) helps.
In this blog post, we’ll look at how DynamoDB Accelerator (DAX ) works, its advantages, and how to use it to make DynamoDB work better.
DynamoDB Accelerator (DAX) is an in-memory cache for DynamoDB that accelerates the read performance of your tables. As an external caching layer, DAX can reduce the time it takes to retrieve frequently accessed data by caching it in memory. Unlike traditional caching layers, which require setup and maintenance, DAX is fully managed by AWS and integrates seamlessly with DynamoDB.
With DAX, applications can achieve up to a 10x reduction in read latency especially for read-heavy and repeated read workloads.
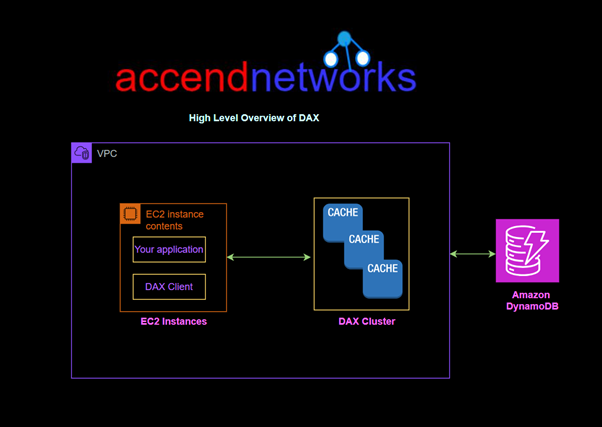
DAX sits between your application and DynamoDB tables, functioning as an in-memory cache for read requests. When your application queries data, DAX first checks if the requested data is available in the cache:
Amazon DynamoDB Accelerator (DAX) is designed to run within an Amazon Virtual Private Cloud (Amazon VPC) environment.
To run your application, you launch an Amazon EC2 instance into your Amazon VPC. You then deploy your application (with the DAX client) on the EC2 instance.
Fully Managed and Highly Available: DAX is fully managed by AWS, meaning you won’t have to worry about infrastructure management, setup, or maintenance.
In-Memory Caching for Microsecond Latency: As an in-memory cache for DynamoDB, DAX stores recently accessed data in memory, significantly improving data retrieval speeds.
Seamless Integration with DynamoDB APIs: One of DAX’s standout features is that it seamlessly integrates with existing DynamoDB APIs, meaning it doesn’t require changes to application logic.
Configurable Cache TTL (Time to Live): DAX uses a default TTL of five minutes, which means cached data will automatically expire after five minutes to ensure consistency with DynamoDB. However, TTL can be adjusted to meet application needs, allowing you to balance cache freshness and retrieval speed.
DAX is ideal for read-heavy workloads where latency is critical and immediate consistency is not required. Some popular use cases include:
DAX is priced based on the hourly usage of nodes in your cluster, and additional charges apply for data transfer. While there is an upfront cost for using DAX, the reduction in DynamoDB read requests can lead to significant savings over time, particularly for read-intensive applications.
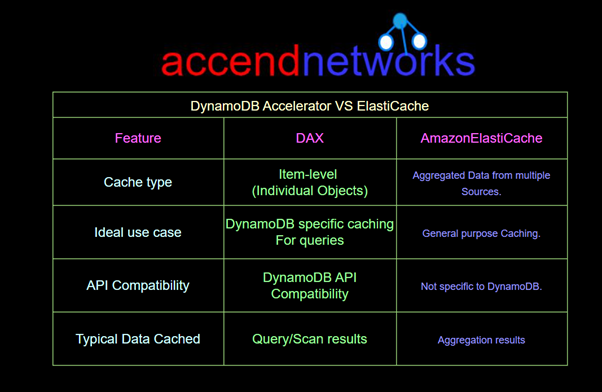
While DAX serves as an in-memory cache for individual DynamoDB items, Amazon ElastiCache is a more general-purpose caching solution, suitable for caching complex, aggregated data from multiple sources. Here’s a quick comparison
Conclusion
DynamoDB Accelerator (DAX) is a powerful tool for reducing read latency, optimizing costs, and delivering seamless performance for read-heavy applications. By leveraging in-memory caching, DAX offers a way to handle high-traffic workloads without sacrificing speed or scalability.
Thanks for reading and stay tuned for more.
If you have any questions concerning this article or have an AWS project that requires our assistance, please reach out to us by leaving a comment below or email us at sales@accendnetworks.com.
Thank you!